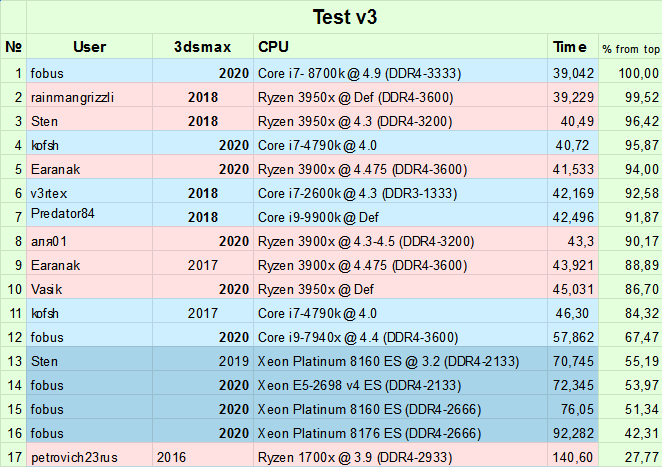
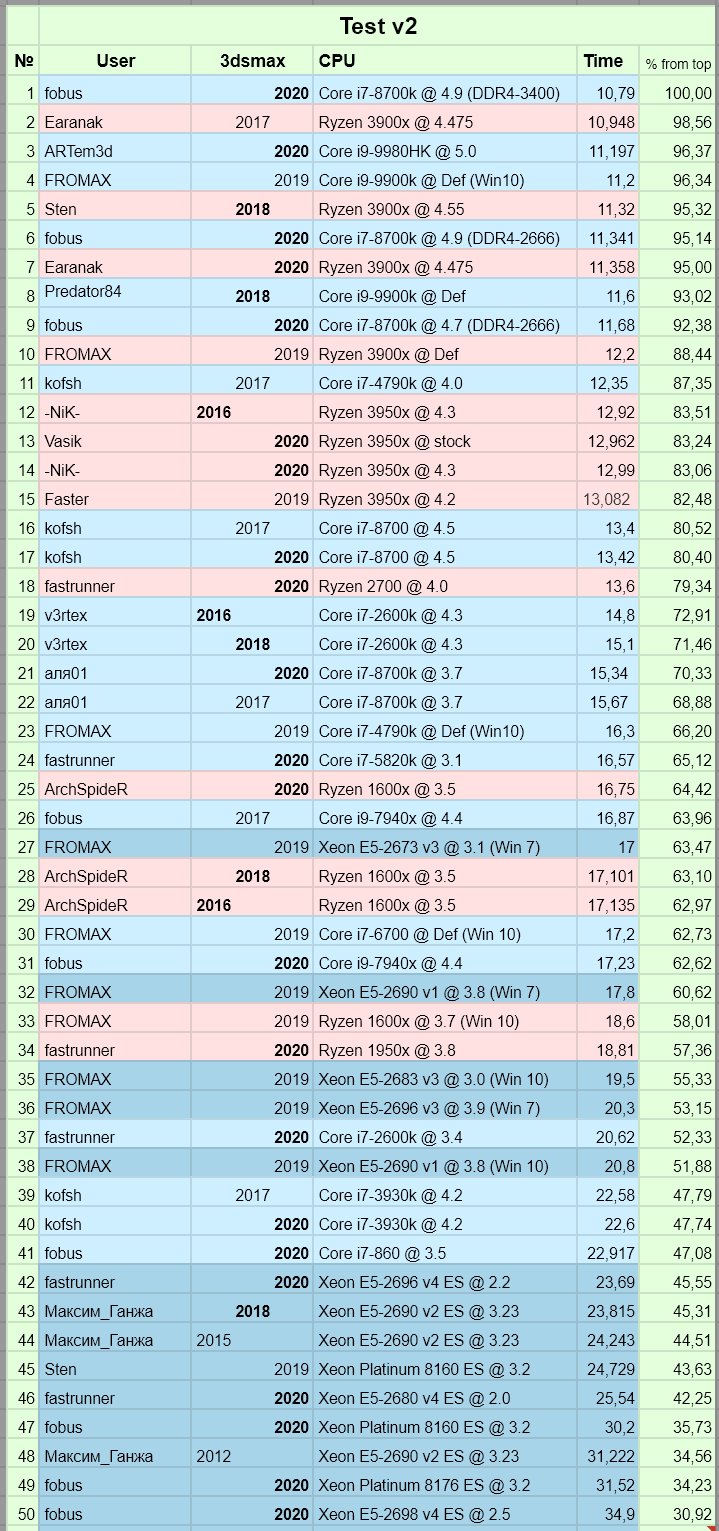
Решил обновить систему, но никак не могу выбрать подходящий процессор.
Я занимаюсь только моделингом, а большинство тестов в интернете затрагивают только скорость просчета. В силу своей специфики 3d Max использует в большинстве случаев только одно ядро для задач моделирования.
Исходя из этого я провел несколько тестов и выявил, что разные процессоры, в силу разных тактовых частот и инструкций, показывают разное время при выполнении задач на одном ядре. Для того, чтобы выяснить какой процессор именно в 3ds max будет быстрее на этом злосчастном одном ядре мне помогли сделать скрипт (спасибо -NiK-
), который задействует одно ядро для копирования большого количества объектов и вычисляет время его выполнения.
Что бы начать тест нужно в процессах максу оставить только одно ядро и запустить скрипт, к результату дописать версию макса и название процессора и частоту.
Очень интересны результаты любых процессоров и производителей.
для моделинга в максе самое главное - частота на 1 ядро в бусте, остальное не имеет значения
для кручения вьюпорта - основное видюха
это при условии, что ядро в бусте совпало с процессом макса (т.е. было к нему привязано на время производимых в максе манипуляций). А такое далеко не всегда бывает. Хотя в последних виндовсках конечно, работают в этом направлении.
Но пара лет назад было забавно. Буститься нифига не делающее ядро, а на том что чтото делает - обычная средняя частота.
Забавные кстати результаты теста, если им можно доверять. AMD Лидирует на один поток. Гы. Дожили.
Забавные кстати результаты теста, если им можно доверять
Я бы доверял этим результатам гораздо меньше чем cinebench 20
где райзен тоже лидирует. Действительно дожили :)
Сравнение между версиями 3дмаксов очень сомнительно. Автодеск умеют не только ухудшать, но и улучшать (возможно случайно). В разных версиях скрипты могут выдавать разное время. Добавим к этому разное поведение винды с ядрами и получаем дичь вместо результатов. Синтетика как-то надёжней в этом плане.
Забавные кстати результаты теста, если им можно доверять
Я бы доверял этим результатам гораздо меньше чем cinebench 20
где райзен тоже лидирует. Действительно дожили :)
Сравнение между версиями 3дмаксов очень сомнительно. Автодеск умеют не только ухудшать, но и улучшать (возможно случайно). В разных версиях скрипты могут выдавать разное время. Добавим к этому разное поведение винды с ядрами и получаем дичь вместо результатов. Синтетика как-то надёжней в этом плане.
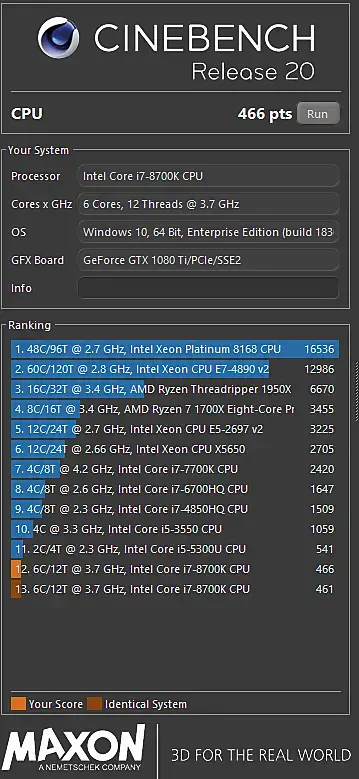
Я бы Cinebench не доверял на 100% в данном контексте. По результатам на данный момент разброс в максе по времени гораздо больше, чем в Cinebench.
К примеру мой 8700k @ 4.7 выдает в Cinebench R20 Single-core результат в ~465 баллов. При этом во втором тесте тут он выигрывает у Ryzen, которые больше 500 баллов по Cinebench имеют.
По результатам на данный момент разброс в максе по времени гораздо больш
Проблема теста не столько в неадекватном замере времени, сколько в неадекватности самих операций. Что клонирование 150 000 инстансов, что турбосмус на 8 итераций, ничего из этого не говорит о том, как в реальности моделируется на том или ином процессоре. Моё мнение - практически одинаково. Есть вещи поважнее. Видеокарта (вьюпорт), ssd (быстрее сохранение). Ну и вообще не одним моделированием наверное процессор будет занят.
Попытка найти "лучший процессор для моделинга в максе" изначально немного странная. В моделировании практически нет операций, которые могут настолько нагрузить процессор, чтобы это стало важным фактором при его выборе. Если рендерить не нужно, то я бы просто выбрал недорогой неприхотливый проц. И свежую версию 3дмакса кстати.
Наблюдения: Первый тест частично выполняется с применением AVX, при том, что второй без них идет. Соответственно в первом тесте частота вначале теста ниже (у меня -300МГц стоит смещение).
По результатам на данный момент разброс в максе по времени гораздо больш
Проблема теста не столько в неадекватном замере времени, сколько в неадекватности самих операций. Что клонирование 150 000 инстансов, что турбосмус на 8 итераций, ничего из этого не говорит о том, как в реальности моделируется на том или ином процессоре. Моё мнение - практически одинаково. Есть вещи поважнее. Видеокарта (вьюпорт), ssd (быстрее сохранение). Ну и вообще не одним моделированием наверное процессор будет занят.
Попытка найти "лучший процессор для моделинга в максе" изначально немного странная. В моделировании практически нет операций, которые могут настолько нагрузить процессор, чтобы это стало важным фактором при его выборе. Если рендерить не нужно, то я бы просто выбрал недорогой неприхотливый проц. И свежую версию 3дмакса кстати.
Ну почему же. К процессорам АМД была масса претензий в свое время, что типа, в однопотоке они не очень, есть фризы и т.д. и для моделирования лучше подходят процессоры Intel. Многие даже сейчас упорно покупают 10 серию I9, типа, этоже интел, там все быстрее и надежней и все такое прочая.
По сабжевому тесту - все далеко не так однозначно.
Конечно, возможно операции выбраны не самые показательные. Плюс еще и геометрия мелкая - наверняка 3000 райзенам влазит в кеш целиком.
Возможно - какие то оптимизации есть в максе, из серии - если 1000 одинаковых операций с одним и тем же фефектом - то пропускаем какие нибудь расчетные стадии.
поэтому, более показательно было бы взять серьезную геометрию и применить над ней штук 50 осмысленных модификаторов и операций последовательно, как это и происходит в реальном проекте, с отключением вывода графики (видимо redraw off), и предварительном исследовании вопроса - нужно ли принудительно привязывать макс к ядру процессора (выставлении affinity), или и так сойдет.
Видеокарта кстати, по сдешному опыту не особо значима - поэтому одно время в сборках рекомендовали как более чем достаточную - 1050ti.
То есть стресс-тесты типа турбосмуса на 8 итераций входят в задачи по моделированию, а многопоточная симуляция ткани в марве не входит? А потом появляется какой-нибудь условный 3dsmax 2024 с поддержкой многопоточности на каких-нибудь модификаторах :)
Если бы было чуть понятней, что конкретно означает "моделирование" для ТС, то можно было бы проводить более адекватные тесты. А пока эти замеры в попугаях не более показательны, чем cinebench, а изменения в maxscript между версиями макса их вообще обесценивают.
Кто-нибудь может аргументированно объяснить, почему выбор процессора для моделирования это не экономия на спичках? Пример реальной модели, где с одним процессором работать гораздо комфортней чем с другим. Я не моделер.
То есть стресс-тесты типа турбосмуса на 8 итераций входят в задачи по моделированию, а многопоточная симуляция ткани в марве не входит? А потом появляется какой-нибудь условный 3dsmax 2024 с поддержкой многопоточности на каких-нибудь модификаторах :)
Если бы было чуть понятней, что конкретно означает "моделирование" для ТС, то можно было бы проводить более адекватные тесты. А пока эти замеры в попугаях не более показательны, чем cinebench, а изменения в maxscript между версиями макса их вообще обесценивают.
Кто-нибудь может аргументированно объяснить, почему выбор процессора для моделирования это не экономия на спичках? Пример реальной модели, где с одним процессором работать гораздо комфортней чем с другим. Я не моделер.
на серьезных сетках применение модификаторов достаточно заметная вещь. Чем быстрей они работают - тем больше комфорта в работе. Просто набор модификаторов должен быть более менее реалистичным (Приближенным к реальной работе, а не один и тот же в цикле), и тестировать нужно все на одной версии макса, а не один тест на разных.
То есть стресс-тесты типа турбосмуса на 8 итераций входят в задачи по моделированию, а многопоточная симуляция ткани в марве не входит? А потом появляется какой-нибудь условный 3dsmax 2024 с поддержкой многопоточности на каких-нибудь модификаторах :)
Marvelous тут вроде как ни при чем. Kofsh
пишет про производительность в 3dsmax. А уж что там за горами никто не знает.
Пока в 3dsmax действительно только одно ядро используется в большинстве операций при моделировании. И пока это изменится может смениться не одно поколение процессоров. Выбор конкретных модификаторов сделать сложно в силу того, что у каждого свои приоритеты по моделированию и модификаторы тоже разные используются чаще других.
Одно ясно точно, что в 3dsmax скорость именно одного ядра имеет большое значение для моделирования и работы с вьюпортом в целом. И именно недоверие к AMD из прошлого заставляет многих покупать процессоры Intel. Кроме того в цифрах частоты процессоров Intel существенно больше в бусте и это дополнительно поднимает их ценность в свете того, что всего одно ядро с более высокой частотой по идее будет поднимать производительность при моделировании и работе в окнах проекций.
Цитата rainmangrizzli:
и тестировать нужно все на одной версии макса, а не один тест на разных.
Все работают в разных версиях и статистика будет куда более скудной при ограничении како-либо одной. В пределах одной версии по таблице можно тоже сравнить если хочется.
Одно ясно точно, что в 3dsmax скорость именно одного ядра имеет большое значение для моделирования и работы с вьюпортом в целом.
Оно имеет место чисто формально, опираясь на синтетический тест. Но один налитый чай перечёркивает всю эту экономию времени и скорость одного проца над другим, потому что в моделинге 99,9% решают руки, а не проц. А в скорости вьюпорта больше решает организация сцены, нежели проц и видюха. Раньше как-то на кореквадах моделировали всё то же самое.
Ещё, например, такая ресурсоёмкая операция, как Attach нескольких тысяч объектов, будет гораздо сильнее ускорена не мощным процом, а по-другому запрограммированным скриптом.
Одно ясно точно, что в 3dsmax скорость именно одного ядра имеет большое значение для моделирования и работы с вьюпортом в целом.
Оно имеет место чисто формально, опираясь на синтетический тест. Но один налитый чай перечёркивает всю эту экономию времени и скорость одного проца над другим, потому что в моделинге 99,9% решают руки, а не проц. А в скорости вьюпорта больше решает организация сцены, нежели проц и видюха. Раньше как-то на кореквадах моделировали всё то же самое.
Ещё, например, такая ресурсоёмкая операция, как Attach нескольких тысяч объектов, будет гораздо сильнее ускорена не мощным процом, а по-другому запрограммированным скриптом.
Ну вы же понимаете, что это все трах - изза того что ресурсов недостаточно CPU? Этоже не нормально, когда приходиться думать не над эстетикой сцены, а над ее технической посути оптимизации, чтобы не тормозило. Это не то, чем должен заниматься человек творческой профессии.
Цитата fobus:
Цитата rainmangrizzli:
и тестировать нужно все на одной версии макса, а не один тест на разных.
Все работают в разных версиях и статистика будет куда более скудной при ограничении како-либо одной. В пределах одной версии по таблице можно тоже сравнить если хочется.
Какая разница, кто в чем работает? Тест это обособленная вещь. Блендеров тоже куча, но есть cinebench такойто версии, который включает в себя одно зафиксированное рендер ядро, а не все сразу. Есть опять же, SPECapc for Solidworks 2019, for, понимаете? Иначе- у вас будет такая же хрень, как в тесте рендера тутошнем, где я на старом максе и врее на 1950 на 4ггц выдал такой результат, который на минуты отличается от прочих, и никто так и не смог его повторить на таком же оборудование, и смысл таком тесте? Тест должен проводиться в одинаковых условиях и быть воспроизводимым, иначе нуль ему цена.
На сайте c 24.06.2014
Сообщений: 4903
Украина, Одесса
Цитата Yehat:
Attach нескольких тысяч объектов, будет гораздо сильнее ускорена не мощным процом, а по-другому запрограммированным скриптом
Прям прослезился, истинна ) Когда пробовал тысяч ~30 объектов саттачить в один - настрадался. Каждый скрипт который я пробовал делал это все быстрее и быстрее. С 40 минут до 10 минут дошло дело к третьему скрипту. И тогда я узнал что есть обычный стандартный... Который внезапно сделал эту же задачу за 1 минуту )) Ну который - Utilities -> Collapse -> Collapse Selected. Это стало для меня шоком. Тут и вправду. Гони не гони процессор, делай его в 10 раз мощнее, а толку если основной затуп в задаче - сам алгоритм.
Ну вы же понимаете, что это все трах - изза того что ресурсов недостаточно CPU?
Нет, это из-за того, что макс со времён одноядерных процессоров до сих пор не знает, что ядер стало больше. А не из-за того, что скорость этого ядра недостаточная.
Ну вы же понимаете, что это все трах - изза того что ресурсов недостаточно CPU?
Нет, это из-за того, что макс со времён одноядерных процессоров до сих пор не знает, что ядер стало больше. А не из-за того, что скорость этого ядра недостаточная.
На сайте c 24.06.2014
Сообщений: 4903
Украина, Одесса
Жаль что я слишком тупой в моментах понимания принципа работы потоков/ядер. Но я прям всегда недоумевал, почему бы просто не сделать динамическое объединение ядер/потоков. Ну, кэш то все равно инклюзивный (L1/L2 у всех ядер заполнен одинаковой информацией) и доступ к L3 кэшу в тех же 3000 Райзенах сделали почти равномерным по задержкам. Т.е в теории можно сделать какой то динамический режим который брал бы пачку ядер и заставлял бы их работать как одно целое при выполнении однопоточной задачи. Но блин, это все слишком легко звучит, и если бы оно так было то давно бы уже сделали так. Тогда вообще конечно "пушка" была бы, когда какой нить 3990X работает в режиме 64 ядер объединенных в 8 групп и выдает нереальную производительность, а когда дело доходит до рендера, то переключает их в режим 128 отдельных потоков. Ну как то так. Тип создать такого плана механизм и архитектуру, тогда бы и разрабам софта не пришлось бы заморачиваться. Но видать нифига это не просто все так...
В общем что бы это работало как в DirectX 12 - Assync Computing
. Хотя это прям не то об чем я говорю. Это придется делать нереально большой буффер для очереди выполнения команд и что бы все ядра одновременно все фигачили и пускали результаты в одном потоке. Наверное это почти невозможно. Ведь им нужно просчитывать одну и ту же задачу.
Жаль что я слишком тупой в моментах понимания принципа работы потоков/ядер. Но я прям всегда недоумевал, почему бы просто не сделать динамическое объединение ядер/потоков. Ну, кэш то все равно инклюзивный (L1/L2 у всех ядер заполнен одинаковой информацией) и доступ к L3 кэшу в тех же 3000 Райзенах сделали почти равномерным по задержкам. Т.е в теории можно сделать какой то динамический режим который брал бы пачку ядер и заставлял бы их работать как одно целое при выполнении однопоточной задачи. Но блин, это все слишком легко звучит, и если бы оно так было то давно бы уже сделали так. Тогда вообще конечно "пушка" была бы, когда какой нить 3990X работает в режиме 64 ядер объединенных в 8 групп и выдает нереальную производительность, а когда дело доходит до рендера, то переключает их в режим 128 отдельных потоков. Ну как то так. Тип создать такого плана механизм и архитектуру, тогда бы и разрабам софта не пришлось бы заморачиваться. Но видать нифига это не просто все так...
во многих вычислительных задачах результаты нового расчета зависят от предыдущего, поэтому его невозможно или очень сложно распараллелить.
ну и потом, часто накладные расходы на распараллеливание больше выигрыша от самого по себе распараллеливания.