ąØą░ čüą░ą╣č鹥 c 14.06.2012
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 15455
ą£ąŠčüą║ą▓ą░
| ą”ąĖčéą░čéą░ kophysty: ą¤ąŠą┤čāą╝ą░ą╗, čćč鹊 ąĄčüčéčī ąĄčēąĄ ą▓č鹊čĆąŠą╣ ą▓ą░čĆąĖą░ąĮčé, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ąĮą░ą╝ąĮąŠą│ąŠ ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ, ąŠčüąŠą▒ąĄąĮąĮąŠ ąĄčüą╗ąĖ čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ 100+ ą╝ąŠą┤ąĄą╗ąĄą╣, ąĮąŠ ąĖąĘą▒ą░ą▓ąĖčé ąŠčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüč鹊čĆąŠąĮąĮąĖąĄ čüąĄčĆą▓ąĖčüčŗ. ą¦ąĄčĆąĄąĘ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā┬ĀSelenium ą╝ąŠąČąĮąŠ čĆą░ą▒ąŠčéą░čéčī ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ čü ą▒čĆą░čāąĘąĄčĆąŠą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, č鹊ą│ą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą▒čāą┤ąĄčé čüą░ą╝ ą╗ąŠą│ąĖąĮąĖčéčīčüčÅ ąĖ ą▓ą▓ąŠą┤ąĖčéčī čüą▓ąŠąĖ ą┤ą░ąĮąĮčŗąĄ č湥čĆąĄąĘ čüčéą░ąĮą┤ą░čĆčéąĮčāčÄ č乊čĆą╝čā ą▓ ą▒čĆą░čāąĘąĄčĆąĄ. ąöą░ą╗ąĄąĄ ą┐čĆąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄ čüą║čĆąĖą┐čé ąĮą░čćąĮąĄčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ą┐ąĄčĆąĄą▒ąĖčĆą░čéčī ą▓čüąĄ čüčéčĆą░ąĮąĖčåčŗ, čü ą║ąŠč鹊čĆčŗčģ ąĮčāąČąĮąŠ čüąŠą▒čĆą░čéčī ąĖąĮč乊čĆą╝ą░čåąĖčÄ.┬Āą×ą┐čÅčéčī ąČąĄ ą┐ąŠčéčĆąĄą▒čāąĄčéčüčÅ ą▓čĆąĄą╝čÅ, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą┐ąĖčüą░čéčī ąĖ ą┐čĆąŠč鹥čüčéąĖčĆąŠą▓ą░čéčī čüą║čĆąĖą┐čé ą▓ čéą░ą║ąŠą╝ ą▓ą░čĆąĖą░ąĮč鹥. ąØąŠ čģąŠč鹥ą╗ąŠčüčī ą▒čŗ, ą┐čĆąĄąČą┤ąĄ ąŠčåąĄąĮąĖčéčī ą┐ąŠčéčĆąĄą▒ąĮąŠčüčéčī ą▓ čŹčéąĖčģ ą┤ąŠčĆą░ą▒ąŠčéą║ą░čģ, ąĮą░čüą║ąŠą╗čīą║ąŠ ą▓ąŠąŠą▒čēąĄ čüč鹊ąĖčé čŹčéąĖą╝ ąĘą░ąĮąĖą╝ą░čéčīčüčÅ. ąóą░ą║ čŹč鹊 ąĖ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąŠčüąĮąŠą▓ąĮąŠą╣ ą▓ą░čĆąĖą░ąĮčé. ąÆčŗ ąČąĄ ą┐ąŠąĮąĖą╝ą░ąĄč鹥, čćč鹊 ąĮąĖą║č鹊 ą▓ čüą▓ąŠčæą╝ čāą╝ąĄ ąĮąĄ čüąŠą│ą╗ą░čüąĖčéčüčÅ čüą║ą░čĆą╝ą╗ąĖą▓ą░čéčī ąĮąĄąĖąĘą▓ąĄčüčéąĮąŠą╝čā 菹║ąĘąĄčłąĮąĖą║čā čüą▓ąŠčÄ čāčćčæčéą║čā. ąÉ ą▓ čåąĄą╗ąŠą╝ čÅ ąĮąĄ ąĘąĮą░čÄ, ą┐ąŠč湥ą╝čā čüą░ą╝ čüą░ą╣čé ąĮąĄ ą┤ą░čüčé čéą░ą║čāčÄ čüčéą░čéąĖčüčéąĖą║čā ą▓ ą┐čĆąŠčäąĖą╗ąĄ čĹʹĄčĆą░. ąŻą▓ąĄčĆąĄąĮ čéą░ą╝ ąĄčæ ą▓čŗčłąĄ ą║čĆčŗčłąĖ ąĖ ą┤ą▓ą░ ą┐čĆąĖčåąĄą┐ą░ ąĄčēčæ. |
|
ąØą░ čüą░ą╣č鹥 c 02.10.2015
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 1899
ą×ą┤ąĄčüčüą░
ą¤ąŠą╗ąĖčéąĖą║ą░
ąöą░čéą░ ą▓čŗą┤ą░čćąĖ:
06.08.2024 17:58:08
ą¤ąŠąČąĖąĘąĮąĄąĮąĮčŗą╣ ą▒ą░ąĮ
| ąóčāčé ą║č鹊-č鹊 ą┐čĆąŠą┤ą░čæčé čćč鹊-č鹊? |
|
ąØą░ čüą░ą╣č鹥 c 28.05.2015
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 141
ą£ąŠčüą║ą▓ą░
| ą”ąĖčéą░čéą░ Slazzo: JS čüą║čĆąĖą┐čé ą╝ąŠąČąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī čāąČąĄ ą▓ ąĘą░ą╗ąŠą│ąĖąĮąĄąĮčāčÄ čüąĄčüąĖčÄ ąóą░ą║ąŠą╣ ą▓ą░čĆąĖą░ąĮčé ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ čĆąĄčłąĄąĮąĖčÅ čĆą░ąĘąŠą▓čŗčģ ąĘą░ą┤ą░čć, ąĮąŠ ąĮą░ą▓čüą║ąĖą┤ą║čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ JS-čüą║čĆąĖą┐čé ąĮąĄ ą┐ąŠą╝ąŠąČąĄčé čĆąĄčłąĖčéčī ąĮą░čłčā ąĘą░ą┤ą░čćčā, čé.ą║. ą▓ č乊čĆą╝ą░č鹥 ąŠą▒čüčāąČą┤ą░ąĄą╝ąŠą│ąŠ ą▓ą░čĆąĖą░ąĮčéą░ ą╝čŗ čģčĆą░ąĮąĖą╝ ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄą╝ čüčéą░čéąĖčüčéąĖą║čā ą╗ąŠą║ą░ą╗čīąĮąŠ ąĮą░ ą║ąŠą╝ą┐ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ąĢčüą╗ąĖ ą╝čŗ ą▒čāą┤ąĄą╝ ąĘą░ą┐čāčüą║ą░čéčī JS-čüą║čĆąĖą┐čé ą▓ ąĘą░ą╗ąŠą│ąĖąĮąĄąĮąĮąŠą╣ čüąĄčüčüąĖąĖ, ą╝čŗ ąĮąĄ čüą╝ąŠąČąĄą╝ ą▒čĆą░čéčī ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąĖąĘ ą╗ąŠą║ą░ą╗čīąĮčŗčģ .json čäą░ą╣ą╗ąŠą▓, ą▓ ą║ąŠč鹊čĆčŗčģ čģčĆą░ąĮąĖčéčüčÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąŠčé ą┐čĆąĄą┤čŗą┤čāčēąĖčģ čüąĄčüčüąĖą╣. ąÉąĮą░ą╗ąŠą│ąĖčćąĮą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą▓čüčéą░ąĄčé ąĖ čü ą┐ąĄčĆąĄą┤ą░č湥ą╣ čüąŠą▒čĆą░ąĮąĮąŠą╣ čüčéą░čéąĖčüčéąĖą║ąĖ ąŠą▒čĆą░čéąĮąŠ ąĮą░ ą║ąŠą╝ą┐ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▓ .json, ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖ ą▓čŗą│čĆčāąĘą║ąĖ ą▓ .csv. ┬Ā┬Ā Selenium ą┐ąŠą┤ phyton ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ą▓čüąĄ ą┐čĆąĖą╝ąĄčĆąĮąŠ č鹊 ąČąĄ čüą░ą╝ąŠąĄ, ąĮąŠ č鹊ą╗čīą║ąŠ čü ą║ąŠą╝ą┐ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĖ ą▒ąĄąĘ ą║ąŠčüčéčŗą╗ąĄą╣, ą║ąŠč鹊čĆčŗąĄ ąĮą░čü ąŠąČąĖą┤ą░čÄčé ą▓ čüą╗čāčćą░ąĄ čü JS. ąśčüčģąŠą┤ąĮąĖą║ č鹥ą║čāčēąĄą│ąŠ čüą║čĆąĖą┐čéą░:┬Āhttps://github.com/kophysty/3ddd_parse.git ąÆčŗą╗ąŠąČčā čéčāčé ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĮčāčÄ ą▓ąĄčĆčüąĖčÄ čüą║čĆąĖą┐čéą░, ą║ąŠą│ą┤ą░ ą▒čāą┤ąĄčé ą│ąŠč鹊ą▓ą░.┬Ā ą”ąĖčéą░čéą░ sergeykashanin: ą£ąŠąČąĄčé čüč鹊ąĖčé ą┐čĆąĄą┤ą╗ąŠąČąĖčéčī čŹč鹊čé čüą║čĆąĖą┐čé čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ą╝, čćč鹊ą▒ ąŠąĮąĖ ąĄą│ąŠ ą▓ ąøąÜ ąĖąĮč鹥ą│čĆąĖčĆąŠą▓ą░ą╗ąĖ? ą▒čāą┤čā čĆą░ą┤ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī čü ą░ą┤ą╝ąĖąĮąĖčüčéčĆą░čåąĖąĄą╣ čüą░ą╣čéą░, ąĄčüą╗ąĖ ą▒čāą┤ąĄčé┬Āą║ą░ą║ą░čÅ-č鹊┬ĀąŠą▒čĆą░čéąĮą░čÅ čüą▓čÅąĘčī ąĖ čĆą░ą▒ąŠčéą░čéčī ą▓ ąŠąĘą▓čāč湥ąĮąĮčŗčģ čāčüą╗ąŠą▓ąĖčÅčģ, ą░ ą┐ąŠą║ą░ - čĆąĄčłą░ąĄą╝ ą▓ąŠą┐čĆąŠčü, ą║ą░ą║ ą╝ąŠąČąĄą╝┬Ā |
|
ąØą░ čüą░ą╣č鹥 c 14.12.2007
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 850
ąÜčĆą░čüąĮąŠą┤ą░čĆ
| ą”ąĖčéą░čéą░ mr.spoilt: čüčéčĆą░čłąĮąŠ, čüąŠą│ą╗ą░čüąĄąĮ. ąØą░ą┤ąĄčÄčüčī, čćč鹊 ą║ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÄ 34 ą│ąŠą┤ą░ ą┐čĆąĖą║čĆčāčéčÅčé čŹčéčā čäąĖčłą║čā ąĮą░ čüą░ą╣č鹥. čćč鹊 ą┤ąĄą╗ą░čéčī ąĄčüą╗ąĖ čÅ ą▓ąĄčĆčÄ ą▓ ą▒ąĖč鹊ą║ ą║ 34ąŠą╝čā ą│ąŠą┤čā, ą▒ąŠą╗čīčłąĄ č湥ą╝ ą▓ čüčéą░čéąĖčüčéąĖą║čā ą║ 34ąŠą╝čā ą│ąŠą┤čā?! ą┤čāą╝ą░čÄ ąŠčéą▓ąĄčé ą▓čŗ ąĘąĮą░ąĄč鹥 ))) |
|
ąØą░ čüą░ą╣č鹥 c 19.06.2021
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 29
|
ąöą╗čÅ ą┐ąŠą┤ąŠą▒ąĮąŠą╣ ąĘą░ą┤ą░čćąĖ ąĮą░ą┤ąŠ 菹║čüč鹥ąĮčłąĄąĮ ą┤ą╗čÅ ą▒čĆą░čāąĘąĄčĆą░ ą┐ąĖčüą░čéčī ąĮčā ąĖą╗ąĖ ąĮą░ ą║čĆą░ą╣ ąĘą░čüčéą░ą▓ąĖčéčī čĹʹĄčĆą░ čĆą░ąĘ ą▓ n ą╝ąĄčüčÅčåąĄą▓ ąŠčéą║čĆčŗčéčī dev tools (F12) ąĖ čüą║ąŠą┐ąĖčĆąŠą▓ą░čéčī PHPSESSID ą║čāą║čā ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ čüąŠčäčéąĖąĮą░ ą╝ąŠą│ą╗ą░ ąĘą░ą╗ąŠą│ąĖąĮąĖčéčīčüčÅ ąĖ ą┐ą░čĆčüąĖčéčī ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą░ą║ą║ą░čāąĮčéą░.
|
|
ąØą░ čüą░ą╣č鹥 c 28.05.2015
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 141
ą£ąŠčüą║ą▓ą░
| ą”ąĖčéą░čéą░ pocmok: ąĘą░čüčéą░ą▓ąĖčéčī čĹʹĄčĆą░ čĆą░ąĘ ą▓ n ą╝ąĄčüčÅčåąĄą▓ ąŠčéą║čĆčŗčéčī dev tools (F12) ąĖ čüą║ąŠą┐ąĖčĆąŠą▓ą░čéčī PHPSESSID ą║čāą║čā ąöą░ čćč鹊 ą▓čŗ! ┬Āąóčāčé čĆą░ąĘą│ą░ą┤čŗą▓ą░ąĮąĖąĄ ą║ą░ą┐čćąĖ ą▒čāčĆčÄ ąĮąĄą│ąŠą┤ąŠą▓ą░ąĮąĖčÅ ą▓čŗąĘą▓ą░ą╗ąŠ, ą░ ą▓čŗ ą┐čĆąŠ ą┐ąŠąĖčüą║ ąĖ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ą┤ą░ąĮąĮčŗčģ ąĖąĘ dev tools┬Āčüą▓ąŠąĖą╝ąĖ čĆčāą║ą░ą╝ąĖ ą│ąŠą▓ąŠčĆąĖč鹥. Facebook ą┐ąŠ F12 ą▒ąŠą╗čīčłąĖą╝ąĖ ą║čĆą░čüąĮčŗą╝ąĖ ą▒čāą║ą▓ą░ą╝ąĖ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ą░ąĄčé, čćč鹊 čŹč鹊 ąŠą┐ą░čüąĮąŠ. ┬Ā┬Ā┬Ā ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, čĆą░čüčłąĖčĆąĄąĮąĖąĄ ą┤ą╗čÅ ą▒čĆą░čāąĘąĄčĆą░ čüč鹊ą╗ą║ąĮąĄčéčüčÅ čü č鹥ą╝ąĖ ąČąĄ ą┐čĆąŠą▒ą╗ąĄą╝ą░ą╝ąĖ, čćč鹊 ąĖ čüą║čĆąĖą┐čé ąĮą░ JS, ą║ąŠč鹊čĆčŗąĄ čÅ ąŠą┐ąĖčüą░ą╗ ą▓čŗčłąĄ ŌĆō ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąŠą▒ąĮąŠą▓ą╗čÅčéčī ą╗ąŠą║ą░ą╗čīąĮčŗąĄ čäą░ą╣ą╗čŗ ąĮą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą╝ ą║ąŠą╝ą┐ąĄ (ą▓ąĄčĆąĮąĄąĄ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ, ąĮąŠ čŹč鹊 ą▒čāą┤ąĄčé čāąČąĄ ąĮą░čĆčāčłąĄąĮąĖąĄ ą┐čĆą░ą▓ąĖą╗ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą▒čĆą░čāąĘąĄčĆą░). ąÉ čģčĆą░ąĮąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ čüčéą░čéąĖčüčéąĖą║ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ ą│ą┤ąĄ-č鹊 ą║čĆąŠą╝ąĄ ąĖčģ ą║ąŠą╝ą┐ą░ čÅ ą┤ą░ąČąĄ ąĮąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄ ą┐ąŠ čĆčÅą┤čā ąŠč湥ą▓ąĖą┤ąĮčŗčģ ą┐čĆąĖčćąĖąĮ. ┬Ā ąØą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čüą║čĆąĖą┐čé čāąČąĄ ą┐ąĄčĆąĄą┐ąĖčüą░ąĮ ąĮą░ selenium ąĖ ąŠčéą╗ąĖčćąĮąŠ čā ą╝ąĄąĮčÅ čĆą░ą▒ąŠčéą░ąĄčé, čéą░ą║ čćč鹊 čüą║ąŠčĆąŠ ą▓čŗą╗ąŠąČčā ąĄą│ąŠ čéčāčé ą┤ą╗čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ, ąŠčüčéą░ą╗ąŠčüčī č鹊ą╗čīą║ąŠ ą▓ąĖą┤ąŠčü ąĘą░ą┐ąĖčüą░čéčī čü ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĄą╣ čĆą░ą▒ąŠčéčŗ. ┬Ā┬Ā |
|
ąØą░ čüą░ą╣č鹥 c 14.06.2012
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 15455
ą£ąŠčüą║ą▓ą░
| ą”ąĖčéą░čéą░ kophysty: ąØą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čüą║čĆąĖą┐čé čāąČąĄ ą┐ąĄčĆąĄą┐ąĖčüą░ąĮ ąĮą░ selenium ąĖ ąŠčéą╗ąĖčćąĮąŠ čā ą╝ąĄąĮčÅ čĆą░ą▒ąŠčéą░ąĄčé, čéą░ą║ čćč鹊 čüą║ąŠčĆąŠ ą▓čŗą╗ąŠąČčā ąĄą│ąŠ čéčāčé ą┤ą╗čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ, ąŠčüčéą░ą╗ąŠčüčī č鹊ą╗čīą║ąŠ ą▓ąĖą┤ąŠčü ąĘą░ą┐ąĖčüą░čéčī čü ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĄą╣ čĆą░ą▒ąŠčéčŗ. 
|
|
ąØą░ čüą░ą╣č鹥 c 28.05.2015
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 141
ą£ąŠčüą║ą▓ą░
| ą”ąĖčéą░čéą░ Slazzo: ą▓ąĖą┤ąĮąŠ čćč鹊 ą┤ą░ąČąĄ ąĮąĄ ąĖąĮč鹥čĆąĄčüąŠą▓ą░ą╗ąĖčüčī ą▓ąŠą┐čĆąŠčüąŠą╝ ą┐čĆąĄąČą┤ąĄ č湥ą╝ čüą┤ąĄą╗ą░čéčī ą▓čŗą▓ąŠą┤čŗ, ąĄčüčéčī Client-side storage ą║ą░ą║ čĆą░ąĘ ą┤ą╗čÅ JS, ąĄčüčéčī čéą░ą║ąČąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠčŗą▓čéčī čäą░ą╣ą╗ ą┐čĆąĄą┤ą╗ąŠąČąĖčéčī čāąĘąĄčĆčā čüąŠčģčĆą░ąĮąĖčéčī ą▓ čäą░ą╣ą╗ ą▒ąĄąĘ ąĮąĖą║ą░ą║ąĖčģ ą┐ą╗ą░ą│ąĖąĮąŠą▓ ą▓čüąĄ čāąČąĄ ą▓ ą▒čĆą░čāąĘąĄčĆą░čģ ąØąĄ čģąŠčćčā ąĮąĖ čü ą║ąĄą╝ čüąŠčĆąĄą▓ąĮąŠą▓ą░čéčīčüčÅ ąĖ ąĮą░ ąĘą▓ą░ąĮąĖąĄ ą│čāčĆčā ą▓ JS ąĮąĄ ą┐čĆąĄč鹥ąĮą┤čāčÄ. ąØąŠ čüą┐ą░čüąĖą▒ąŠ ąĘą░ ą▓ą░čłąĄ čāčćą░čüčéąĖąĄ, ą┐čĆąĖčÅčéąĮąŠ, čćč鹊 ą▓čüąĄ ą▒ąŠą╗čīčłąĄą╣ ą╗čÄą┤ąĄą╣ ą┐čĆąĄą┤ą╗ą░ą│ą░čÄčé čĆą░ąĘąĮčŗąĄ ą▓ą░čĆąĖą░ąĮčéčŗ čĆąĄčłąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ. ąĀąĄčćčī čłą╗ą░ ąĖą╝ąĄąĮąĮąŠ ąŠą▒ ą░ą▓č鹊ąĮąŠą╝ąĮąŠą╝ čüąŠčģčĆą░ąĮąĄąĮąĖąĖ čäą░ą╣ą╗ąŠą▓ čüą░ą╝ąŠą╣ čüąŠčäčéąĖąĮąŠą╣ ą┐ąŠ ąĘą░ą┤ą░ąĮąĮąŠą╣ čüčéčĆčāą║čéčāčĆąĄ ą┐ą░ą┐ąŠą║. ą» ą┐ąŠąĮąĖą╝ą░čÄ, čćč鹊 ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé ąĖ čüą░ą╝ čāą║ą░ąĘą░čéčī ą┐čāčéčī ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čäą░ą╣ą╗ą░ ąĖ čŹč鹊čé ą▓ą░čĆąĖą░ąĮčé čāą┤ąŠą▒ąĄąĮ ą▓ čüą╗čāčćą░ąĄ, ąĄčüą╗ąĖ ąĮčāąČąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī ąŠą┤ąĖąĮ-ą┤ą▓ą░ ąŠčéą┤ąĄą╗čīąĮčŗčģ čäą░ą╣ą╗ą░. ąØąŠ ą╗ąŠą│ąĖą║ą░ ą╝ąŠąĄą│ąŠ čüą║čĆąĖą┐čéą░ ą┐ąŠčüčéčĆąŠąĄąĮą░ čéą░ą║, čćč鹊 ąŠąĮ ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé ą╗ąŠą║ą░ą╗čīąĮčŗąĄ .json čäą░ą╣ą╗čŗ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ čĆą░ąĮąĄąĄ, ąĘą░č鹥ą╝ čüąŠčģčĆą░ąĮčÅąĄčé ąĮąŠą▓čŗą╣ .json ąĖ ą┐ąŠčüą╗ąĄ čŹč鹊ą│ąŠ čüąĮąŠą▓ą░ ą┐ąĄčĆąĄą▒ąĖčĆą░ąĄčé ą╗ąŠą║ą░ą╗čīąĮčŗąĄ .json-čŗ, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī čäąĖąĮą░ą╗čīąĮčŗą╣ .csv. ąĢčüčéčī ąĄčēąĄ čĆčÅą┤ čüčåąĄąĮą░čĆąĖąĄą▓, ą║ąŠč鹊čĆčŗąĄ čéą░ą║ąČąĄ, čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ, ą▓čŗąĘąŠą▓čāčé čéčĆčāą┤ąĮąŠčüčéąĖ. ą£ąŠąČąĄč鹥 ąĘą░ą│ą╗čÅąĮčāčéčī ą▓ ą╝ąŠą╣ Github ąĘą░ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéčÅą╝ąĖ, ąĄčüą╗ąĖ ą▓ą░ą╝ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ąĖąĮč鹥čĆąĄčüąĮąŠ. ąĪąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÄ ąĮčāąČąĮąŠ ą▒čāą┤ąĄčé čāą║ą░ąĘčŗą▓ą░čéčī ą┐čāčéąĖ ąĖ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ .json-ąŠą▓ ą┐čĆąĖ ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ ąĖą╗ąĖ ąŠą▒čĆą░čēąĄąĮąĖąĖ čüą║čĆąĖą┐čéą░ ą║ čäą░ą╣ą╗ą░ą╝. ąÉ čé.ą║. ą▓ ą┐ąĄčĆčüą┐ąĄą║čéąĖą▓ąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą▓ .csv ąĖą╝ąĖą┤ąČąĄą╣ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ, ą║ąŠč鹊čĆčŗąĄ č鹊ąČąĄ ąĮčāąČąĮąŠ ą▒čāą┤ąĄčé čüąĮą░čćą░ą╗ą░ čüąŠčģčĆą░ąĮąĖčéčī ą╗ąŠą║ą░ą╗čīąĮąŠ, ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą│čĆą░čäąĖą║ąŠą▓ ąĖ ą┐čĆąŠčć., č鹊 ąĖ ą┤ą╗čÅ čŹč鹊ą│ąŠ čéą░ą║ąČąĄ ą┐ąŠčéčĆąĄą▒čāčÄčéčüčÅ ą┤ąŠą┐. ą┤ąĄą╣čüčéą▓ąĖčÅ ąŠčé ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ąÜą░ą║ ą┐ąŠ ą╝ąĮąĄ, č鹊 ą▓čüąĄ čŹč鹊 ąŠč湥ąĮčī čüą╗ąŠąČąĮąŠ. ą¤ąŠą║ą░ ą╝ąĮąĄ čŹčéą░ čüčģąĄą╝ą░ ą▓ąĖą┤ąĖčéčüčÅ čéčāą┐ąĖą║ąŠą▓ąŠą╣. ┬Ā┬Ā ą¤ąŠčŹč鹊ą╝čā ąĮą░ ą┤ą░ąĮąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé čüą║čĆąĖą┐čé ąĮą░ą┐ąĖčüą░ąĮ ąĖą╝ąĄąĮąĮąŠ ąĮą░ python. ąöą░, ąĄčüčéčī čüą▓ąŠąĖ ąĮčÄą░ąĮčüčŗ, ąĮąŠ ą┐ąŠą║ą░ čÅ čüčćąĖčéą░čÄ, čćč鹊 ą┤ą╗čÅ ą┐ą░čĆčüąĖąĮą│ą░/ą░ąĮą░ą╗ąĖąĘą░ čŹč鹊 ąŠą┐čéąĖą╝ą░ą╗čīąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé. |
|
ąØą░ čüą░ą╣č鹥 c 23.01.2021
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 70
ą┐ąŠą╗ąĖčéąĖą║ą░
ąöą░čéą░ ą▓čŗą┤ą░čćąĖ:
06.08.2024 17:58:08
ą¤ąŠąČąĖąĘąĮąĄąĮąĮčŗą╣ ą▒ą░ąĮ
| ą▓ąŠčé ąĄčüą╗ąĖ ą▒čŗ čéčŗ ą┐čĆąĖą┤čāą╝ą░ą╗ čüčéą░čéąĖčüčéąĖą║čā čā ą║ąŠą│ąŠ čćč鹊 ą╗čāčćčłąĄ ą┐čĆąŠą┤ą░ąĄčéčüčÅ - ąĖ čüą░ą╝ąŠąĄ ą▓ą░ąČąĮąŠąĄ "ąÜąÉąÜ" ąŠč鹊 ą▒čŗą╗ąŠ ą▒čŗ ą▓ąĄčüąĄą╗ąĄąĄ)ą» ą▒čŗ ą┤ą░ąČąĄ čüą║ą░ąĘą░ą╗ čüą░ą╝čā ąĖą┤ąĄčÄ - ą░ ąĮąĄ ąĮą░ą┐ąĖčüą░ąĮąĖąĄ - čÅ ą▒čŗ ąĮą░ ą┐ąĖč鹊ąĮčćąĖą║ąĄ č鹥ą▒ąĄ ą▒čŗ ąĮą░čłą║čĆčÅą▒ą░ą╗ ą▒čŗ ą║ąŠą┤ąĖčłą║čā.. ąÉ čéą░ą║ čłčéčāą║ą░ 50:50. ą×ąĮ č鹊 čüąĖčüč鹥ą╝ą░čéąĖąĘąĖčĆčāąĄčé ą▓čüąĄ ą┐čĆąŠą┤ą░ąČąĖ ą▓ ą║ą░čĆčéąĖąĮčā -┬Ā ąĮąŠ ą▓ąĄą┤čī čüąŠą│ą╗ą░čüąĖčłčī ą║čāą┤ą░ ąĖąĮč鹥čĆąĄčüąĮąĄą╣ čćč鹊 ą╗čāčćčłąĄ ą┐čĆąŠą┤ą░ąĄčéčīčüčÅ čā čüąŠčüąĄą┤ą░) ąĖą╗ąĖ ąĄčēąĄ ą╗čāčćčłąĄ) čüčéą░čéąĖčüą║čā ą┐ąŠ ąĘą░ą┐čĆąŠčüą░ą╝ ą▓ ą┐ąŠąĖčüą║ąŠą▓ąĖą║ąĄ)ąŚą░ą┐čĆąŠčüčŗ - ą┤ąĮčÅąĘą░ą┐čĆąŠčüčŗ - ąĮąĄą┤ąĄą╗ąĖąĘą░ą┐čĆąŠčüčŗ - ą╝ąĄčüčÅčåą░┬Ā)) |
|
ąØą░ čüą░ą╣č鹥 c 19.06.2021
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 29
| ąÆąŠčé č鹊ą╗čīą║ąŠ ą║ą░ą║ ą▒čāą┤čāčé čüčĆą░ą▓ąĮąĖą▓ą░čéčīčüčÅ ą┐čĆąŠą┤ą░ąČąĖ ą╝ąŠą┤ąĄą╗ąĄą╣ ąĘą░ą│čĆčāąČąĄąĮąĮčŗčģ ą▓ čĆą░ąĘąĮčŗą╣ ą┐ąĄčĆąĖąŠą┤ ą▓čĆąĄą╝ąĄąĮąĖ. ą¤ąĄčĆą▓ą░čÅ ą╝ąŠą┤ąĄą╗čī ą┐čĆąŠą┤ą░ą▓ą░ą╗ą░čüčī čü 50% ąŠčéčćąĖčüą╗ąĄąĮąĖčÅą╝ąĖ, ą░ ą▓č鹊čĆą░čÅ ą║ ą┐čĆąĖą╝ąĄčĆčā čü 55% ąĖ ą▒ą×ą╗čīčłą░čÅ čüčāą╝ą╝ą░ čü ąĄąĄ ą┐čĆąŠą┤ą░ąČ ą╝ąŠąČąĄčé ą▓ą▓ąĄčüčéąĖ ą▓ ąĘą░ą▒ą╗čāąČąĄąĮąĖąĄ. |
|
ąØą░ čüą░ą╣č鹥 c 28.05.2015
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 141
ą£ąŠčüą║ą▓ą░
| ąÜą░ą║ ąŠą▒ąĄčēą░ą╗, ąŠą▒ąĮąŠą▓ąĖą╗ čüą║čĆąĖą┐čé ąĖ ąĘą░ą┐ąĖčüą░ą╗ ą▓ąĖą┤ąĄąŠ čü ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĄą╣ ąĄą│ąŠ čĆą░ą▒ąŠčéčŗ. ą×čéą║čĆčŗčéčŗą╣ ą║ąŠą┤ čüą║čĆąĖą┐čéą░ ą╝ąŠąČąĄč鹥 ą┐ąŠčüą╝ąŠčéčĆąĄčéčī / čüą║ą░čćą░čéčī čü ą╝ąŠąĄą│ąŠ čĆąĄą┐ąŠąĘąĖč鹊čĆąĖčÅ ąĮą░ GitHub: https://github.com/kophysty/3ddd-parser-selenium ąōąŠč鹊ą▓čŗą╣ ą║ čĆą░ą▒ąŠč鹥 čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ exe-čłąĮąĖą║ čü čĆą░ą▒ąŠč湥ą╣ čüčéčĆčāą║čéčāčĆąŠą╣ ą┐ą░ą┐ąŠą║ ą╝ąŠąČąĮąŠ čüą║ą░čćą░čéčī ąĘą┤ąĄčüčī:https://disk.yandex.ru/d/IU099FZV2mjujQ ąÆąĖą┤ąĄąŠ čü ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĄą╣ čĆą░ą▒ąŠčéčŗ:┬Āhttps://www.youtube.com/watch?v=2st2JEMZ_yY ąźąŠč鹥ą╗ čüąĮą░čćą░ą╗ą░ ąĘą░č鹥čĆąĄčéčī čåąĖčäčĆčŗ ą▓ ą▓ąĖą┤ąĄąŠ, ąĮąŠ ą▒ąĄąĘ ąĮąĖčģ, ąĮą░ ą╝ąŠą╣ ą▓ąĘą│ą╗čÅą┤, čüą╝čŗčüą╗ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ čāą▒ąĖą▓ą░ąĄčéčüčÅ ąĮą░ą┐čĆąŠčćčī. ą¤ą╗čÄčü, ą┐ąŠą┤čāą╝ą░ą╗ čÅ, ą╝ąŠąČąĄčé ą▒čŗčéčī, čüą┤ąĄą╗ą░čÄ ą┐čĆąĖčÅčéąĮąŠąĄ ą║ąŠą╝čā-č鹊, ą║č鹊 čéą░ą║ čģąŠč鹥ą╗ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī ąĮą░ čćčāąČčāčÄ čüčéą░čéąĖčüčéąĖą║čā ą┐čĆąŠą┤ą░ąČ. ą£ąĮąĄ ąŠčüąŠą▒ąŠ čģą▓ą░čüčéą░čéčīčüčÅ ąĮąĄ č湥ą╝, ąĮąŠ čü ą┤čĆą░ąĮąŠą╣ ąŠą▓čåčŗ ŌĆō čģąŠčéčī čłąĄčĆčüčéąĖ ą║ą╗ąŠą║ )┬Ā ąĢčēąĄ čĆą░ąĘ ą▓ ą┤ą▓čāčģ čüą╗ąŠą▓ą░čģ ąŠčüąĮąŠą▓ąĮąŠąĄ ą┐ąŠ čĆą░ą▒ąŠč鹥 čüą║čĆąĖą┐čéą░: 1.┬Ā┬Ā┬Ā┬Ā ąŚą░ą┐čāčüą║ą░ąĄą╝ čüą║čĆąĖą┐čé 2.┬Ā┬Ā┬Ā┬Ā ąøąŠą│ąĖąĮąĖą╝čüčÅ ą▓ ą▒čĆą░čāąĘąĄčĆąĄ, ąĮą░ąČąĖą╝ą░ąĄą╝ ą▒čāą║ą▓čā ŌĆśyŌĆÖ ąĖ ąĘą░č鹥ą╝ Enter 3.┬Ā┬Ā┬Ā┬Ā ąĪą║čĆąĖą┐čé čüąŠą▒ąĖčĆą░ąĄčé čüčéą░čéąĖčüčéąĖą║čā ą┐čĆąŠą┤ą░ąČ ąĖąĘ ą▓ą░čłąĄą│ąŠ ą░ą║ą║ą░čāąĮčéą░ 4.┬Ā┬Ā┬Ā┬Ā ąÆ ą┐ą░ą┐ą║ąĄ ŌĆ£ResultŌĆØ cąŠčģčĆą░ąĮčÅąĄčéčüčÅ .csv čäą░ą╣ą╗ čüąŠ ą▓čüąĄą╣ čüąŠą▒čĆą░ąĮąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ 5.┬Ā┬Ā┬Ā┬Ā ą¤čĆąĖ ą┐ąŠą▓č鹊čĆąĮąŠą╝ ąĘą░ą┐čāčüą║ąĄ čüą║čĆąĖą┐čé čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé čüąŠčģčĆą░ąĮąĄąĮąĮąŠąĄ čĆą░ąĮąĄąĄ čü č鹥ą║čāčēąĖą╝ąĖ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅą╝ąĖ ą▓ ą░ą║ą║ą░čāąĮč鹥 ąĖ čüąŠąĘą┤ą░ąĄčé ąĮąŠą▓čŗą╣ čäą░ą╣ą╗ čü ąĮąŠą▓ąŠą╣ ą┤ą░č鹊ą╣. (ąĄčüą╗ąĖ čüą║čĆąĖą┐čé ą┐ąŠą▓č鹊čĆąĮąŠ ąĘą░ą┐čāčēąĄąĮ ą▓ čŹč鹊čé ąČąĄ ą┤ąĄąĮčī, č鹊 .csv čü č鹥ą║čāčēąĄą╣ ą┤ą░č鹊ą╣ ą┐čĆąŠčüč鹊 ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ) ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā * č鹥ą┐ąĄčĆčī ą▒ąĄčĆąĄą│ąĖč鹥 ą┐ą░ą┐ą║čā ŌĆ£datesŌĆØ, čéą░ą║ ą▓ ąĮąĄą╣ čģčĆą░ąĮąĖčéčüčÅ ą▓čüčÅ ą▓ą░čłą░ čüąŠą▒čĆą░ąĮąĮą░čÅ čĆą░ąĮąĄąĄ čüčéą░čéąĖčüčéąĖą║ą░. ą¤ąĄčĆąĄą┤ čüąŠąĘą┤ą░ąĮąĖąĄą╝ .csv čäą░ą╣ą╗ąŠą▓ čüą║čĆąĖą┐čé ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé ąĖą╝ąĄąĮąĮąŠ ąĄąĄ. |
|
ąØą░ čüą░ą╣č鹥 c 14.06.2012
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 15455
ą£ąŠčüą║ą▓ą░
|
* ą░ ąĄčüą╗ąĖ ąĮąĄ čāą▒ąĄčĆčæą│? ąØąĄ čäą░čéą░ą╗čīąĮąŠ ąČąĄ?
|
|
ąØą░ čüą░ą╣č鹥 c 28.05.2015
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 141
ą£ąŠčüą║ą▓ą░
| ą”ąĖčéą░čéą░ Yehat: * ą░ ąĄčüą╗ąĖ ąĮąĄ čāą▒ąĄčĆčæą│? ąØąĄ čäą░čéą░ą╗čīąĮąŠ ąČąĄ? ą┤ą░ ąĮąĄčé, ą║ąŠąĮąĄčćąĮąŠ. ą¤čĆąŠčüč鹊 č鹊ą│ą┤ą░ ą▓ąŠ-ą┐ąĄčĆą▓čŗčģ: čüčéą░čéąĖčüčéąĖą║ą░ ą┐čĆąŠą┤ą░ąČ ąŠą┐čÅčéčī čĆą░čüčüčćąĖčéą░ąĄčéčüčÅ ąĖčüčģąŠą┤čÅ ąĖąĘ čāčüčĆąĄą┤ąĮąĄąĮąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣, ą░ ąĮąĄ č鹊čćąĮčŗčģ; ą▓č鹊čĆąŠą╣ ą╝ąŠą╝ąĄąĮčé: ąĮąĄą╗čīąĘčÅ ą▒čāą┤ąĄčé čüąŠčüčéą░ą▓ąĖčéčī čüčĆą░ą▓ąĮąĖč鹥ą╗čīąĮčāčÄ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║čā ą┐čĆąŠą┤ą░ąČ ąĮą░ 3ddd ąĖ 3dsky ąĘą░ ą┐čĆąĄą┤čŗą┤čāčēąĖą╣ ą┐ąĄčĆąĖąŠą┤. ą» ą┐ą╗ą░ąĮąĖčĆčāčÄ ą┤ąŠą▒ą░ą▓ąĖčéčī čéą░ą║ąŠą╣ ą┐ąŠą║ą░ąĘą░č鹥ą╗čī ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ą▓ ą▒ą╗ąĖąČą░ą╣čłąĄąĄ ą▓čĆąĄą╝čÅ┬Ā |
|
ąØą░ čüą░ą╣č鹥 c 20.04.2014
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 1595
ąĀąŠčüčüąĖčÅ!
| ą×ąĮąŠ ą▓čĆąŠą┤ąĄ ąĖąĮč鹥čĆąĄčüąĮąŠ, ąĮąŠ ą▓čĆąŠą┤ąĄ ąĖ ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 č鹥ą║čāčēąĖąĄ ą┤ą░ąĮąĮčŗąĄ ąŠč湥ąĮčī ąĮąĄč鹊čćąĮčŗąĄ. ąóąŠčćąĮčŗą╝ąĖ ąĖčģ ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī, ąĄčüą╗ąĖ čüą┐ą░čĆčüąĖčéčī ąĖ čĆą░ą▒ąŠčéą░čéčī čü ą┤ą░ąĮąĮčŗą╝ąĖ, ą▓ąŠ ą▓ą║ą╗ą░ą┤ą║ąĄ "ąśčüč鹊čĆąĖčÅ ąŠą┐ąĄčĆą░čåąĖą╣", čéą░ą╝ ą┐čĆąĖ ą║ą╗ąĖą║ąĄ ą┐ąŠ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąŠčéą║čĆčŗą▓ą░ąĄčéčüčÅ čéą░ą▒ą╗ąĖčåą░ čü č鹊čćąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ, ą┤ą░č鹊ą╣ ą┐čĆąŠą┤ą░ąČ ąĖ čåąĄąĮąŠą╣ ą┐čĆąŠą┤ą░ąČąĖ. ą» ą▓ąĄą┤čā ą┐ąŠą╗ąĮčŗą╣ čāč湥čé ą┐ąŠ ą▓čüąĄą╝ čüč鹊ą║ą░ą╝ čü 2012 ą│ąŠą┤ą░, ą┐čĆą░ą▓ą┤ą░ ą▓čüąĄ čŹč鹊 ą▓ 菹║čüąĄą╗ąĄ, ąĮąŠ ąĄčüčéčī čĆčÅą┤ ą┐čĆąŠą▒ą╗ąĄą╝, ą║ąŠč鹊čĆčŗąĄ čÅ ą┐ąŠą║ą░ ąĮąĄ čĆąĄčłąĖą╗, ą┐čĆąŠčüč鹊 ą┐ąŠč鹊ą╝čā čćč鹊 菹║čüąĄą╗čī čāąČąĄ ą┐ą╗ą░č湥čé, ą║ąŠą│ą┤ą░ čÅ ąĄą│ąŠ ąĘą░čüčéą░ą▓ą╗čÅčÄ ą▓čüąĄ čüčćąĖčéą░čéčī.┬Ā ą£ąŠąČąĄčé čā ąÆą░čü ąĄčüčéčī ąĖą┤ąĄąĖ, ą▓ č湥ą╝ ą╝ąŠąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čāč湥čé ą▒ąŠą╗čīčłąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą╝ąŠą┤ąĄą╗ąĄą╣? ą» ą▓ąŠčé ąĮą░ Access čüą╝ąŠčéčĆčÄ, ąĮąŠ čéą░ą╝ ąĮą░ą┤ąŠ ą╝ąĮąĄ čĆą░ąĘą▒ąĖčĆą░čéčīčüčÅ. |
|
ąØą░ čüą░ą╣č鹥 c 28.05.2015
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 141
ą£ąŠčüą║ą▓ą░
| ą”ąĖčéą░čéą░ mr.spoilt: ąóąŠčćąĮčŗą╝ąĖ ąĖčģ ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī, ąĄčüą╗ąĖ čüą┐ą░čĆčüąĖčéčī ąĖ čĆą░ą▒ąŠčéą░čéčī čü ą┤ą░ąĮąĮčŗą╝ąĖ, ą▓ąŠ ą▓ą║ą╗ą░ą┤ą║ąĄ "ąśčüč鹊čĆąĖčÅ ąŠą┐ąĄčĆą░čåąĖą╣", čéą░ą╝ ą┐čĆąĖ ą║ą╗ąĖą║ąĄ ą┐ąŠ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąŠčéą║čĆčŗą▓ą░ąĄčéčüčÅ čéą░ą▒ą╗ąĖčåą░ čü č鹊čćąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ, ą┤ą░č鹊ą╣ ą┐čĆąŠą┤ą░ąČ ąĖ čåąĄąĮąŠą╣ ą┐čĆąŠą┤ą░ąČąĖ. ąÆą░čā. ąĪą┐ą░čüąĖą▒ąŠ ą▓ą░ą╝ ąĘą░ čŹč鹊čé ą┐ąŠčüčé, ą▓čŗ ą╝ąĮąĄ ą┐čĆąŠčüč鹊 ą│ą╗ą░ąĘą░ ąŠčéą║čĆčŗą╗ąĖ (ą▓ąĄčĆąŠčÅčéąĮąŠ, ąĮąĄ č鹊ą╗čīą║ąŠ ą╝ąĮąĄ). ą», č湥čüčéąĮąŠ, ąĮąĄ ąĘąĮą░ą╗, čćč鹊 ą▓čüąĄ ą┐čĆąŠą┤ą░ąČąĖ ą┐ąŠ ą▓čüąĄą╝ ą╝ąŠą┤ąĄą╗čÅą╝ čģčĆą░ąĮčÅčéčüčÅ ąĮą░ čüą░ą╣č鹥 ą▓ čéą░ą║ąŠą╝ ą▓ąĖą┤ąĄ.┬Āą» ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄ, ą║ą░ą║ąĖą╝ ą┤čīčÅą▓ąŠą╗čīčüą║ąĖą╝ čüą╝ąĄčģąŠą╝ čüą╝ąĄčÅą╗ąĖčüčī ą░ą┤ą╝ąĖąĮčŗ, ą║ąŠą│ą┤ą░ ąĮą░ą▒ą╗čÄą┤ą░ą╗ąĖ ąĘą░ ąĮą░čłąĖą╝ąĖ ą┐ąŠčéčāą│ą░ą╝ąĖ čĆą░čüčüčćąĖčéą░čéčī čĆą░ąĮąĮąĖąĄ ą┐čĆąŠą┤ą░ąČąĖ.┬Ā┬Ā ą¦č鹊 ąČ. ą¤čĆąĖą┤ąĄčéčüčÅ čüąĮąŠą▓ą░ ą┐ąĄčĆąĄą┐ąĖčüą░čéčī čüą║čĆąĖą┐čé, ąĮąŠ čāąČąĄ ąŠčüąĮąŠą▓čŗą▓ą░čÅčüčī ąĮą░ č鹊čćąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą┐čĆąŠą┤ą░ąČ ą▓čüąĄčģ ą╝ąŠą┤ąĄą╗ąĄą╣.┬Ā ąÉ ą┐ąŠ ą┐ąŠą▓ąŠą┤čā čüą║ąŠčĆąŠčüčéąĖ čĆą░ą▒ąŠčéčŗ excel, ą┤čāą╝ą░čÄ, ą┐čĆąŠą▒ą╗ąĄą╝ą░ čĆąĄčłąĖčéčüčÅ, čé.ą║. ą▓čüąĄ čåąĖčäčĆčŗ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ čā ąĮą░čü ą▒čāą┤ąĄčé čüčćąĖčéą░čéčī python, ą░ ąĮąĄ excel. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, .csv čüą░ą╝ ą┐ąŠ čüąĄą▒ąĄ ą╗ąĄą│č湥, č湥ą╝ .xlsx, ą┐ąŠčŹč鹊ą╝čā ąŠčéą║čĆčŗą▓ą░čéčīčüčÅ č鹊ąČąĄ ą▒čŗčüčéčĆąĄąĄ ą▒čāą┤ąĄčé.┬Ā ┬Ā |
|
ąØą░ čüą░ą╣č鹥 c 19.06.2021
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 29
| ą”ąĖčéą░čéą░ mr.spoilt: 菹║čüąĄą╗čī čāąČąĄ ą┐ą╗ą░č湥čé, ą║ąŠą│ą┤ą░ čÅ ąĄą│ąŠ ąĘą░čüčéą░ą▓ą╗čÅčÄ ą▓čüąĄ čüčćąĖčéą░čéčī.
ą¦č鹊ąČ čā ą▓ą░čü ąĘą░ ąŠą▒čŖąĄą╝ ą┤ą░ąĮąĮčŗčģ čéą░ą║ąŠą╣? ąśą╗ąĖ ą╝ąŠąČąĄčé ą║ą░ą║ąĖąĄ-č鹊 č乊čĆą╝čāą╗čŗ čüąĖą╗čīąĮąŠ čüą╗ąŠąČąĮčŗąĄ?
|
|
ąØą░ čüą░ą╣č鹥 c 28.05.2015
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 141
ą£ąŠčüą║ą▓ą░
| ą”ąĖčéą░čéą░ Slazzo: č鹊ą╗čīą║ąŠ čā ą╝ąĄąĮčÅ ą▓ "ąśčüč鹊čĆąĖčÅ ąŠą┐ąĄčĆą░čåąĖą╣" č鹊ą╗čīą║ąŠ ą▓čŗą▓ąŠą┤ čüčĆąĄą┤čüčéą▓ ąĘąĮą░čćąĖčéčüčÅ, ąĖ ą▓ "ąĪčéą░čéąĖčüčéąĖą║ąĄ ą┐čĆąŠą┤ą░ąČ" č鹊ą╗čīą║ąŠ ąĖčüč鹊čĆąĖčÅ ą┐ąŠčüą╗ąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ą▓čŗą▓ąŠą┤ą░?┬Ā┬Ā ą▓čüąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ - čŹč鹊 ą░ą║čéąĖą▓ąĮčŗąĄ čüčüčŗą╗ą║ąĖ, ą▓ąĮčāčéčĆčī ą┐čĆąŠą▓ą░ą╗ąĖą▓ą░ąĄč鹥čüčī ąĖ čéą░ą╝ ą┐čĆąŠą┤ą░ąČąĖ ą▒čāą┤čāčé |
|
ąØą░ čüą░ą╣č鹥 c 20.04.2014
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 1595
ąĀąŠčüčüąĖčÅ!
| ą”ąĖčéą░čéą░ pocmok: ą”ąĖčéą░čéą░ mr.spoilt: 菹║čüąĄą╗čī čāąČąĄ ą┐ą╗ą░č湥čé, ą║ąŠą│ą┤ą░ čÅ ąĄą│ąŠ ąĘą░čüčéą░ą▓ą╗čÅčÄ ą▓čüąĄ čüčćąĖčéą░čéčī.
ą¦č鹊ąČ čā ą▓ą░čü ąĘą░ ąŠą▒čŖąĄą╝ ą┤ą░ąĮąĮčŗčģ čéą░ą║ąŠą╣? ąśą╗ąĖ ą╝ąŠąČąĄčé ą║ą░ą║ąĖąĄ-č鹊 č乊čĆą╝čāą╗čŗ čüąĖą╗čīąĮąŠ čüą╗ąŠąČąĮčŗąĄ? ą£ąĮąŠą│ąŠ čéčŗčüčÅčć ą┐čĆąŠą┤ą░ąČ, ąĮą░ čĆą░ąĘąĮčŗčģ čüč鹊ą║ą░čģ, ą┐ąŠ ą║ą░ąČą┤ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ąĖą┤ąĄčé čĆą░čüč湥čé ąĄąĄ čüč鹊ąĖą╝ąŠčüčéąĖ, ą┐čĆąĖ čŹč鹊ą╝ čüąĄčéčŗ čĆą░ąĘą▒ąĖčéčŗ ą┐čĆąŠą┐ąŠčĆčåąĖąŠąĮą░ą╗čīąĮąŠ ąĮą░ ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮčŗąĄ ą╝ąŠą┤ąĄą╗ąĖ, ą▓ ąŠą▒čēąĄą╝, čā ą╝ąĄąĮčÅ ą┐ąŠ ą╝ąŠą┤ąĄą╗ąĖ ą│čĆą░čäąĖą║ ą┐čĆąŠą┤ą░ąČ ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī, ąŠą║čāą┐ą░ąĄą╝ąŠčüčéčī, ą┐ąŠč鹊ą╝čā čćč鹊 čÅ čéą░ą║ąČąĄ čĆą░ą▒ąŠčéą░čÄ ą┐ąŠ čéą░ą╣ą╝ąĄčĆčā ąĖ ąĮą░ ą║ą░ąČą┤čŗąĄ ą╝ąŠą┤ąĄą╗ąĖ čā ą╝ąĄąĮčÅ ąĄčüčéčī ąĘą░čéčĆą░č湥ąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ, čéą░ą║ąČąĄ čā ą╝ąĄąĮčÅ čćą░čüčéčī čĆą░ą▒ąŠčéčŗ ą▓čŗą┐ąŠą╗ąĮčÅą╗ą░čüčī ą┐ąŠą╝ąŠčēąĮąĖčåąĄą╣ ąĖ ąŠąĮą░ čü ą┐čĆąŠą┤ą░ąČ čüąŠą▓ą╝ąĄčüčéąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ąĖą╝ąĄąĄčé čüą▓ąŠą╣ ą┐čĆąŠčåąĄąĮčé, ą┐ąŠčŹč鹊ą╝čā ąĖ ą┐čĆąŠčåąĄąĮčé ą▓čŗčüčćąĖčéčŗą▓ą░ąĄčéčüčÅ. ąóą░ą║ąČąĄ čÅ čüčćąĖčéą░čÄ ą║ąŠą╝ąĖčüčüąĖąĖ ąĖ čćąĖčüčéčāčÄ ą┐čĆąĖą▒čŗą╗čī, ą║ąŠčĆąŠč湥, čéą░ą╝ ą╝ąĮąŠą│ąŠ ą▓čüąĄą│ąŠ. ą£ąŠąČąĄčé ą┐ąŠą║ą░ąĘą░čéčīčüčÅ, čćč鹊 čŹč鹊 ą▓čüąĄ ą┐čāčüčéą░čÅ čéčĆą░čéą░ ą▓čĆąĄą╝ąĄąĮąĖ ąĖ čéčāčé čÅ ą┐čĆąŠą╝ąŠą╗čćčā, ąĮąŠ ąĮą░ ą▓čüąĄ čŹč鹊 čÅ ą┐ąŠčéčĆą░čéąĖą╗ čüąŠą▓čüąĄą╝ ąĮąĄą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ą░ ą▓ąĮąĄčüąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓čĆčāčćąĮčāčÄ ą▒ąĄąĘ ą┐ą░čĆčüąĄčĆą░ - ą┤ąĄą╗ąŠ ą┤ą▓čāčģ ą╝ąĖąĮčāčé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čüč鹊ą║ą░ ąĖ čŹč鹊 ąŠą▒čŗčćąĮąŠ čÅ ą┤ąĄą╗ą░čÄ ą▓ ą┤ąĄąĮčī ą▓čŗą┐ą╗ą░čéčŗ. ąÜ č鹊ą╝čā ąČąĄ čÅ ąĄčēąĄ čü ą┤ą▓čāą╝čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅą╝ąĖ čĆą░ą▒ąŠčéą░čÄ ą┐ąŠ ą┤čĆčāą│ąŠą╣ ą┤ąĄčÅč鹥ą╗čīąĮąŠčüčéąĖ, čéą░ą╝ č鹊ąČąĄ čāč湥čé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĮąŠą│ąŠ, ą░ą▓ą░ąĮčüčŗ, ąĘą┐, ą▓ ąŠą▒čēąĄą╝, ąĮąĄąĮą░ą▓ąĖąČčā ą▒čāčģą│ą░ą╗č鹥čĆąĖčÄ, ąĮąŠ ą┐čĆąĖčłą╗ąŠčüčī ąĄąĄ ą▓ąĄčüčéąĖ.┬Ā┬Ā |
|
ąØą░ čüą░ą╣č鹥 c 14.06.2012
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 15455
ą£ąŠčüą║ą▓ą░
|
ąŚą░ ą│čĆą░čäąĖą║ąĖ ą┐ą╗čÄčüąĖą║!
|
|
ąØą░ čüą░ą╣č鹥 c 20.04.2014
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 1595
ąĀąŠčüčüąĖčÅ!
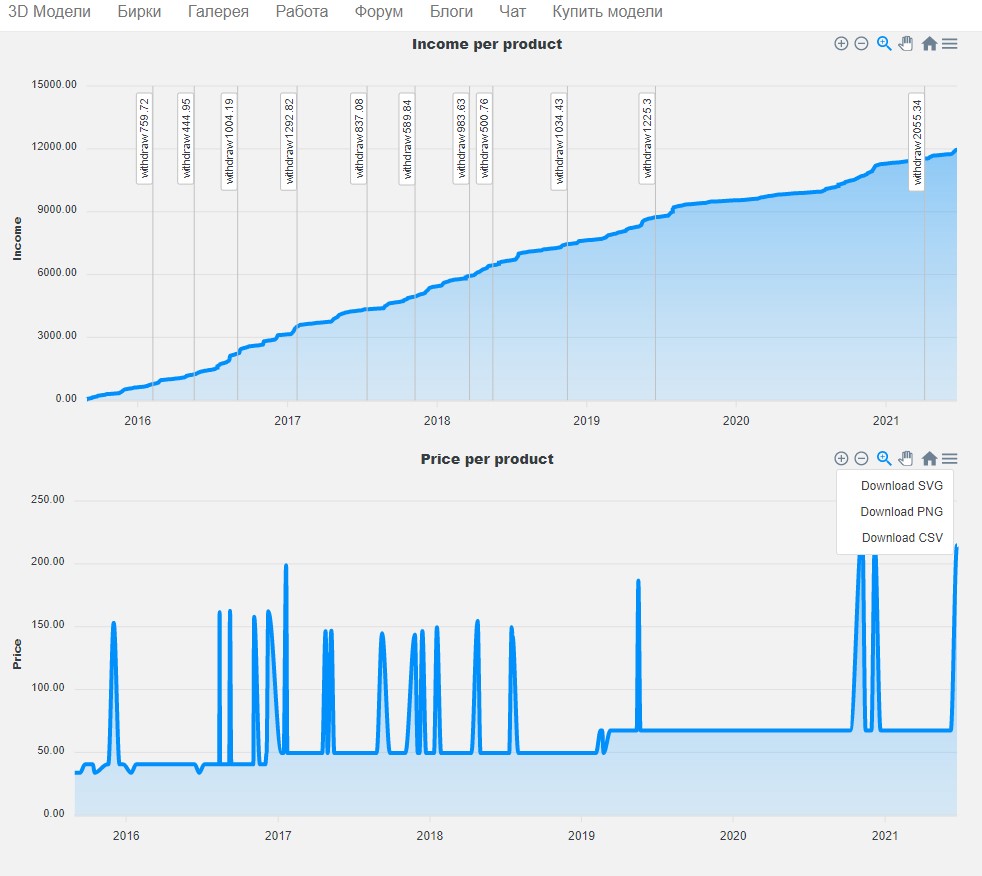
| ą”ąĖčéą░čéą░ Slazzo: ą”ąĖčéą░čéą░ kophysty: ą▓čüąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ - čŹč鹊 ą░ą║čéąĖą▓ąĮčŗąĄ čüčüčŗą╗ą║ąĖ, ą▓ąĮčāčéčĆčī ą┐čĆąŠą▓ą░ą╗ąĖą▓ą░ąĄč鹥čüčī ąĖ čéą░ą╝ ą┐čĆąŠą┤ą░ąČąĖ ą▒čāą┤čāčé ą┐čĆąĖą╝ąĄčĆąĮąŠ 200 ą╗ąĖąĮąĖą╣ JS čüą║čĆąĖą┐čé čü ą│čĆą░čäąĖą║ą░ą╝ąĖ ąĖ ą┐ą░čĆčüąĄčĆą░ą╝ąĖ, ą┐ąŠą║ą░ čćč鹊 ąĮąĄ ą┤ąŠą┤ąĄą╗ą░ąĮąĮčŗą╣ ąĮąŠ čāąČąĄ čĆą░ą▒ąŠčćąĖą╣, ąĖ čā ą╝ąĄąĮčÅ ą║ čüąŠąČąĄą╗ąĄąĮčÄ č鹊ą╗čīą║ąŠ ąŠą┤ąĮą░ ą╝ąŠą┤ąĄą╗čī ąĮą░ ą┐čĆąŠą┤ą░ąČąĄ ąĮąŠ ą┤ąŠą╗ąČąĮąŠ čĆą░ą▒ąŠčéą░čéčī čģąŠčéčī čü čüąŠčéąĮčÅą╝ąĖ, čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąŠ čåą▓ąĄčéą░ą╝ ąĖ čäąĖą╗čīčéčĆ ą▓čĆąŠą┤ąĄ č鹊ąČąĄ ąĄčüčéčī, ą▓ąĄčĆčéąĖą║ą░ą╗čīąĮčŗąĄ ą╝ą░čĆą║ąĄčĆčŗ čŹč鹊 čüčāą╝ą░ ąĖ ą▓čĆąĄą╝čÅ ą▓čŗą▓ąŠą┤ ą▒ą░ą▒ąŠčüąŠą▓, ąĄčüą╗ąĖ ąĄčüčéčī ąČąĄą╗ą░ąĮąĖąĄ ą┤ąŠą┐ąĖą╗ąĖčéčī ąŠčéą┐ąĖčłąĖč鹥čüčī čÅ čāąČąĄ ąĮą░ čŹč鹊 ą┐ąŠčéčĆą░čéąĖą╗ čćą░čüąĖą║ąŠą▓ 4 ąĖ ąŠą┐ąŠąĘą┤ą░ą╗ ą▓ ą┐ą░ą▒┬Ā┬Ā 
) ąØąŠčĆą╝ą░ą╗čīąĮąŠ. 4 ą¦ą░čüą░, ąĮčā ą┤ą░ąČąĄ ąĄčüą╗ąĖ čāą▓ąĄą╗ąĖčćąĖčéčī čüčĆąŠą║ ą▓ 10 čĆą░ąĘ ąĮą░ č鹥čüčéčŗ, ą▒ą░ą│ąĖ, ą┤ąŠą┐ąĖą╗ąĖą▓ą░ąĮąĖčÅ, čćč鹊-č鹊 ą╝ąĮąĄ ą│ąŠą▓ąŠčĆąĖčé, čćč鹊 ą░ą┤ą╝ąĖąĮąĖčüčéčĆą░čåąĖčÅ ą┐čĆąŠčüč鹊 ąĮąĄ ą┤ąĄą╗ą░ąĄčé čüčéą░čéąĖčüčéąĖą║čā ą┤ą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣, ąĮąĄ ą┐ąŠč鹊ą╝čā čćč鹊 čüą╗ąŠąČąĮąŠ, ą░ ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąŠč鹊ą╝čā. ąŁč鹊 ąĀą░čüčłąĖčĆąĄąĮąĖąĄ ą┤ą╗čÅ ą▒čĆą░čāąĘąĄčĆą░? |
|