
–Θ–Μ―É―΅―à–Α–Β–Φ 3D –Μ―é–¥–Β–Ι –Ϋ–Α ―Ä–Β–Ϋ–¥–Β―Ä–Β ―¹ –Ω–Ψ–Φ–Ψ―â―¨―é –Ϋ–Β–Ι―Ä–Ψ―¹–Β―²–Η
–Ξ–Ψ―΅―É –Ω–Ψ–Κ–Α–Ζ–Α―²―¨ ―¹–Ω–Ψ―¹–Ψ–±, –Κ–Α–Κ –Η–Ζ –Ϋ–Β–Κ―Ä–Α―¹–Η–≤―΄―Ö 3–¥ –Μ―é–¥–Β–Ι –Ϋ–Α ―Ä–Β–Ϋ–¥–Β―Ä–Β ―¹–¥–Β–Μ–Α―²―¨ ―³–Ψ―²–Ψ―Ä–Β–Α–Μ–Η―¹―²–Η―΅–Ϋ―΄―Ö, –±―É–Κ–≤–Α–Μ―¨–Ϋ–Ψ –≤ –Ϋ–Β―¹–Κ–Ψ–Μ―¨–Κ–Ψ –Κ–Μ–Η–Κ–Ψ–≤. –†–Β―΅―¨ –Ω–Ψ–Ι–¥―ë―² –Ψ –Ϋ–Β–Ι―Ä–Ψ―¹–Β―²–Η Stable Diffusion (SD).

–≠–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Η―Ä–Ψ–≤–Α―²―¨ –±―É–¥–Β–Φ –Ϋ–Α –Ω―Ä–Η–Φ–Β―Ä–Β –Ψ–¥–Ϋ–Ψ–Ι –Η–Ζ –Ω–Ψ―¹–Μ–Β–¥–Ϋ–Η―Ö ―Ä–Α–±–Ψ―² –≤ –≥–Α–Μ–Β―Ä–Β–Β. –ù–Α –Φ–Ψ–Φ–Β–Ϋ―² –Ϋ–Α–Ω–Η―¹–Α–Ϋ–Η―è ―¹―²–Α―²―¨–Η ―Ä–Α–±–Ψ―²–Α –Ζ–Α–Ϋ–Η–Φ–Α–Β―² –≥–Ψ―Ä―É 3–¥–¥–¥, –Ϋ–Ψ –Η–Φ–Β–Β―² –±–Ψ–Μ―¨―à–Ψ–Β –Κ–Ψ–Μ–Η―΅–Β―¹―²–≤–Ψ –Κ–Ψ–Φ–Φ–Β–Ϋ―²–Α―Ä–Η–Β–≤ –Κ―Ä–Η―²–Η–Κ―É―é―â–Η―Ö –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α–Ϋ–Η–Β –≤ –Ϋ–Β–Ι 3–¥ –Μ―é–¥–Β–Ι. –£―΄–≥–Μ―è–¥―è―² –Ψ–Ϋ–Η –Η –Ω―Ä–Α–≤–¥–Α –Ϋ–Β –Ψ―΅–Β–Ϋ―¨ ―Ö–Ψ―Ä–Ψ―à–Ψ. –ü–Ψ–Ω―Ä–Ψ–±―É–Β–Φ –Η―¹–Ω―Ä–Α–≤–Η―²―¨ ―ç―²–Ψ―² –Φ–Ψ–Φ–Β–Ϋ―².
–ü–Β―Ä–≤―΄–Φ –¥–Β–Μ–Ψ–Φ –Ϋ–Β–Ψ–±―Ö–Ψ–¥–Η–Φ–Ψ ―É―¹―²–Α–Ϋ–Ψ–≤–Η―²―¨ SD –Ϋ–Α ―¹–≤–Ψ–Ι –ü–ö. –ü―Ä–Ψ―Ü–Β―¹―¹ ―É―¹―²–Α–Ϋ–Ψ–≤–Κ–Η –Ψ–Ω–Η―¹―΄–≤–Α―²―¨ –Ϋ–Β –±―É–¥―É ―².–Κ. –≤ –Η–Ϋ―²–Β―Ä–Ϋ–Β―²–Β –¥–Ψ―¹―²–Α―²–Ψ―΅–Ϋ–Ψ –Φ–Ϋ–Ψ–≥–Ψ –Η–Ϋ―³–Ψ―Ä–Φ–Α―Ü–Η–Η –Ϋ–Α ―ç―²―É ―²–Β–Φ―É (–Β―¹–Μ–Η –≤―¹―ë ―²–Α–Κ–Η –Ϋ–Β–Ψ–±―Ö–Ψ–¥–Η–Φ–Ψ ―¹–Ψ–Ζ–¥–Α―²―¨ –Η–Ϋ―¹―²―Ä―É–Κ―Ü–Η―é –Ω–Ψ ―É―¹―²–Α–Ϋ–Ψ–≤–Κ–Β - –Ω–Η―à–Η―²–Β, –Β―¹–Μ–Η –Φ–Ϋ–Ψ–≥–Η–Φ –±―É–¥–Β―² –Ω–Ψ–Μ–Β–Ζ–Ϋ–Ψ ―²–Ψ –Ω–Ψ―¹―²–Α―Ä–Α―é―¹―¨ ―¹–¥–Β–Μ–Α―²―¨). –î–Μ―è –≥–Β–Ϋ–Β―Ä–Α―Ü–Η–Η –±―É–¥–Β–Φ –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α―²―¨ –Φ–Ψ–¥–Β–Μ―¨ Reliberate 2.0. –ï―ë –Ϋ―É–Ε–Ϋ–Ψ ―¹–Ψ―Ö―Ä–Α–Ϋ–Η―²―¨ –≤ –Ω–Α–Ω–Κ–Β ":\Stable Diffusion\stable-diffusion-webui\models\Stable-diffusion". –î–Α–Μ–Β–Β –Ζ–Α–Ω―É―¹–Κ–Α–Β–Φ SD (–Ψ―²–Κ―Ä―΄–≤–Α–Β―²―¹―è –≤ –±―Ä–Α―É–Ζ–Β―Ä–Β) –Η –≤–Η–¥–Η–Φ –Η–Ϋ―²–Β―Ä―³–Β–Ι―¹:
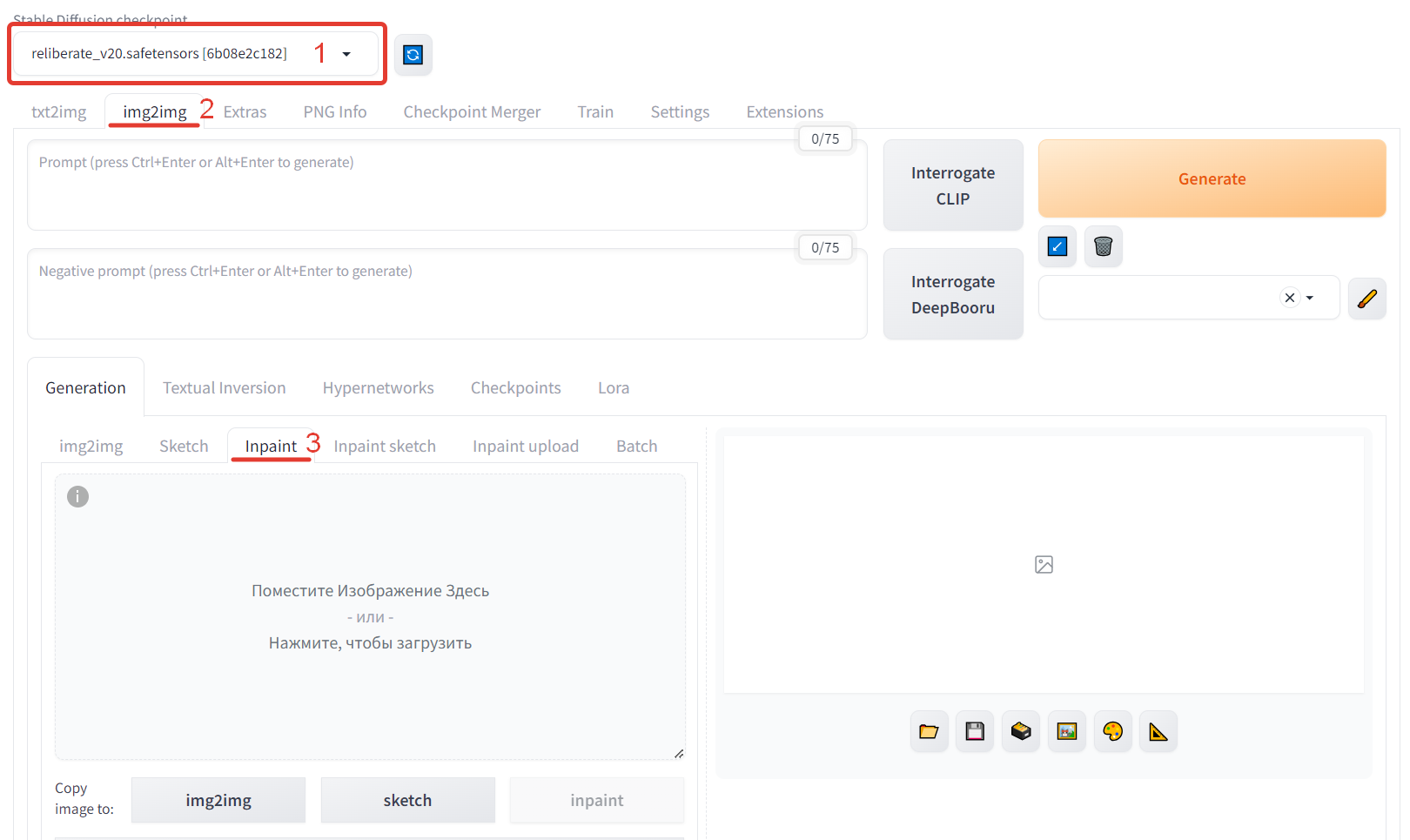
1. –£ –≤–Β―Ä―Ö–Ϋ–Β–Φ –Μ–Β–≤–Ψ–Φ ―É–≥–Μ―É –Η–Ζ –≤―΄–Ω–Α–¥–Α―é―â–Β–≥–Ψ ―¹–Ω–Η―¹–Κ–Α –≤―΄–±–Η―Ä–Α–Β–Φ ―¹–Κ–Α―΅–Α–Ϋ–Ϋ―É―é –Φ–Ψ–¥–Β–Μ―¨ Reliberate_v2.0.
2. –ü–Β―Ä–Β―Ö–Ψ–¥–Η–Φ –Ϋ–Α –≤–Κ–Μ–Α–¥–Κ―É img2img.
3. –ù–Α –≤–Κ–Μ–Α–¥–Κ–Β Generation –≤―΄–±–Η―Ä–Α–Β–Φ ―Ä–Β–Ε–Η–Φ Inpaint. –Δ–Α–Κ –Φ―΄ ―¹–Φ–Ψ–Ε–Β–Φ –≤―΄–±―Ä–Α―²―¨ –Κ–Ψ–Ϋ–Κ―Ä–Β―²–Ϋ–Ψ ―²―É –Ψ–±–Μ–Α―¹―²―¨, –Κ–Ψ―²–Ψ―Ä―É―é –±―É–¥–Β–Φ –≥–Β–Ϋ–Β―Ä–Η―Ä–Ψ–≤–Α―²―¨.
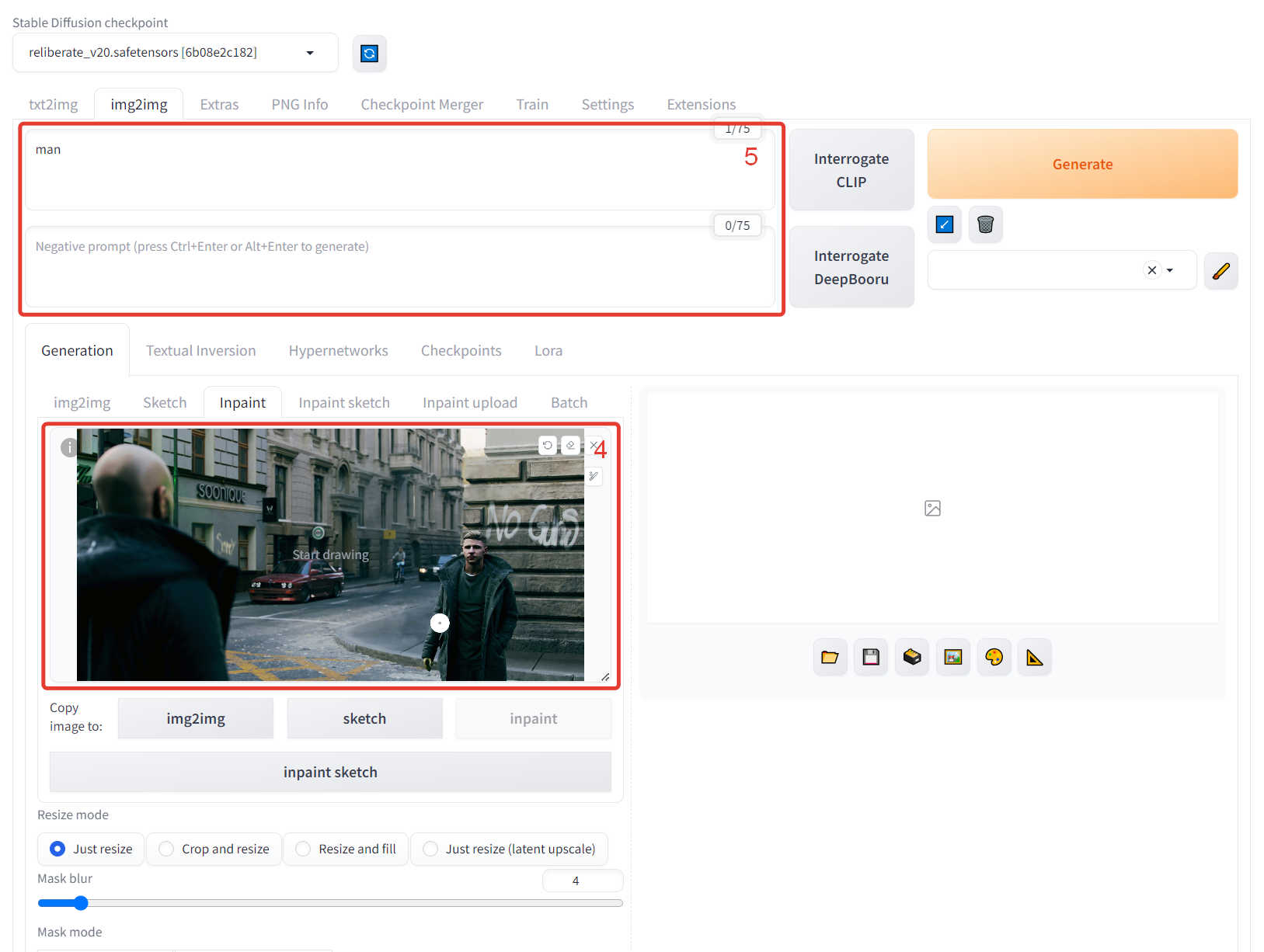
4. –½–Α–≥―Ä―É–Ε–Α–Β–Φ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Β.
5. –ü–Η―à–Β–Φ –Ω–Ψ–¥―¹–Κ–Α–Ζ–Κ―É –¥–Μ―è –Ϋ–Β–Ι―Ä–Ψ–Ϋ–Κ–Η (prompt). –£ –≤–Β―Ä―Ö–Ϋ–Β–Φ –Ψ–Κ–Ϋ–Β ―²–Ψ ―΅―²–Ψ ―Ö–Ψ―²–Η–Φ –≤–Η–¥–Β―²―¨, –≤ –Ϋ–Η–Ε–Ϋ–Β–Φ ―²–Ψ ―΅―²–Ψ –Ϋ–Β–Ψ–±―Ö–Ψ–¥–Η–Φ–Ψ –Η―¹–Κ–Μ―é―΅–Η―²―¨. –·, –Κ–Α–Κ –≤–Η–¥–Η―²–Β, ―¹ –Ψ–Ω–Η―¹–Α–Ϋ–Η–Β–Φ ―¹–Η–Μ―¨–Ϋ–Ψ –Ϋ–Β –Ζ–Α–Φ–Ψ―Ä–Α―΅–Η–≤–Α–Μ―¹―è.
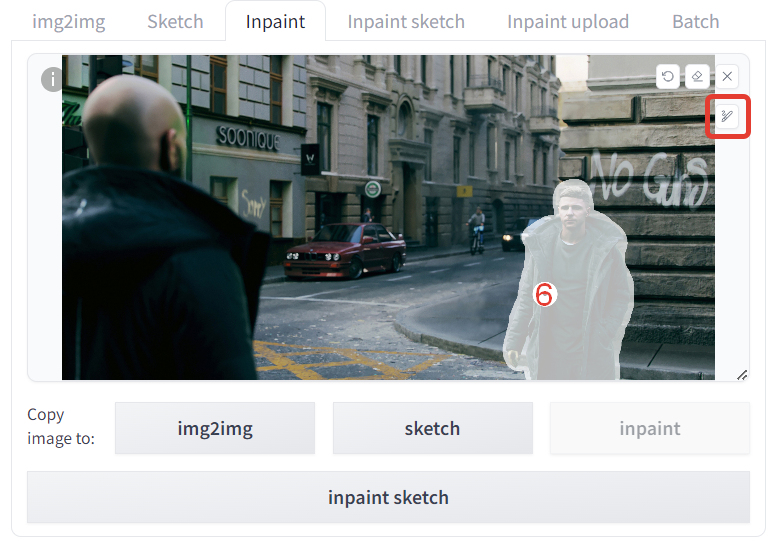
6. –Γ –Ϋ–Β–±–Ψ–Μ―¨―à–Η–Φ –Ζ–Α–Ω–Α―¹–Ψ–Φ –≤―΄–¥–Β–Μ―è–Β–Φ –Ω–Β―Ä–Ψ–Φ –Ψ–±–Μ–Α―¹―²―¨, –Κ–Ψ―²–Ψ―Ä―É―é ―Ö–Ψ―²–Η–Φ ―¹–Κ–Ψ―Ä―Ä–Β–Κ―²–Η―Ä–Ψ–≤–Α―²―¨.
–Γ–Ω―É―¹–Κ–Α–Β–Φ―¹―è –≤ –Ϋ–Α―¹―²―Ä–Ψ–Ι–Κ–Η –Ϋ–Η–Ε–Β.
7. –£―΄–±–Η―Ä–Α–Β–Φ –Ψ–±–Μ–Α―¹―²―¨ –≥–Β–Ϋ–Β―Ä–Α―Ü–Η–Η Only masked (―²–Ψ–Μ―¨–Κ–Ψ –≤―΄–¥–Β–Μ–Β–Ϋ–Ϋ–Ψ–Β)
8. Sampling metod - DPM++ 2M Karras. –£―Ä–Ψ–¥–Β –Κ–Α–Κ ―Ä–Α–±–Ψ―²–Α–Β―² –Μ―É―΅―à–Β –≤―¹–Β–≥–Ψ, ―É –Φ–Β–Ϋ―è ―¹―²–Ψ―è–Μ –Ω–Ψ ―É–Φ–Ψ–Μ―΅–Α–Ϋ–Η―é.
9. –Θ―¹―²–Α–Ϋ–Α–≤–Μ–Η–≤–Α–Β–Φ ―Ä–Α–Ζ–Φ–Β―Ä –≥–Β–Ϋ–Β―Ä–Η―Ä―É–Β–Φ–Ψ–≥–Ψ ―Ä–Β–Ζ―É–Μ―¨―²–Α―²–Α 768 –Ϋ–Α 768 ―²–Ψ―΅–Β–Κ. –≠―²–Ψ –Φ–Α–Κ―¹–Η–Φ–Α–Μ―¨–Ϋ―΄–Ι ―Ä–Α–Ζ–Φ–Β―Ä –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è ―¹–Ψ–Ζ–¥–Α–≤–Α–Β–Φ–Ψ–≥–Ψ –¥–Α–Ϋ–Ϋ–Ψ–Ι –Ϋ–Β–Ι―Ä–Ψ–Ϋ–Κ–Ψ–Ι, –≤―¹―ë ―΅―²–Ψ –±–Ψ–Μ―¨―à–Β –Ψ–Ϋ–Α ―¹–Κ–Μ–Β–Η–≤–Α–Β―² –Η–Ζ –Κ―É―¹–Ψ―΅–Κ–Ψ–≤. –•–Β–Μ–Α―²–Β–Μ―¨–Ϋ–Ψ ―΅―²–Ψ–±―΄ –≤―΄–¥–Β–Μ–Β–Ϋ–Ϋ–Α―è –Ψ–±–Μ–Α―¹―²―¨ –Ϋ–Α –Ϋ–Α―à–Β–Φ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Η ―¹–Η–Μ―¨–Ϋ–Ψ –Ϋ–Β –Ω―Ä–Β–≤―΄―à–Α–Μ–Α ―ç―²–Ψ–≥–Ψ ―Ä–Α–Ζ–Φ–Β―Ä–Α. –ï―¹–Μ–Η –Ψ–Ϋ–Α –±―É–¥–Β―² –±–Ψ–Μ―¨―à–Β ―²–Ψ ―¹–≥–Β–Ϋ–Β―Ä–Η―Ä–Ψ–≤–Α–Ϋ–Ϋ–Ψ–Β –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Β 768*768 –Ω―Ä–Ψ―¹―²–Ψ –±―É–¥–Β―² ―Ä–Α―¹―²―è–Ϋ―É―²–Ψ, ―΅―²–Ψ –Φ–Ψ–Ε–Β―² –Ω–Ψ–≤–Μ–Η―è―²―¨ –Ϋ–Α –Κ–Α―΅–Β―¹―²–≤–Ψ.
10. CFG Scale - ―ç―²–Ψ –≤–Β–Μ–Η―΅–Η–Ϋ–Α ―¹–Ψ–Ψ―²–≤–Β―²―¹―²–≤–Η―è ―²–Β–Κ―¹―²–Ψ–≤–Ψ–Φ―É –Ζ–Α–Ω―Ä–Ψ―¹―É. –ß–Β–Φ –≤―΄―à–Β, ―²–Β–Φ –±–Μ–Η–Ε–Β –Ζ–Α–Ω―Ä–Ψ―à–Β–Ϋ–Ϋ―΄–Ι ―Ä–Β–Ζ―É–Μ―¨―²–Α―², –Ϋ–Ψ –≤–Φ–Β―¹―²–Β ―¹ ―²–Β–Φ –Η –±–Ψ–Μ–Β–Β ―à―É–Φ–Ϋ―΄–Ι. –· –Ψ―¹―²–Α–≤–Η–Μ ―ç―²–Ψ –Ζ–Ϋ–Α―΅–Β–Ϋ–Η–Β –Ω–Ψ ―É–Φ–Ψ–Μ―΅–Α–Ϋ–Η―é.
11. Denoising strenght - ―¹―²–Β–Ω–Β–Ϋ―¨ –Ψ―²–Μ–Η―΅–Η―è –Ϋ–Ψ–≤–Ψ–≥–Ψ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è –Ψ―² –Η―¹―Ö–Ψ–¥–Ϋ–Ψ–≥–Ψ, –≥–¥–Β 0 - –Ψ―²―¹―É―²―¹―²–≤–Η–Β –Η–Ζ–Φ–Β–Ϋ–Β–Ϋ–Η–Ι, –Α 1 - –Ω–Ψ–Μ–Ϋ–Ψ―¹―²―¨―é –Ϋ–Ψ–≤–Α―è –Κ–Α―Ä―²–Η–Ϋ–Κ–Α. –Θ –Φ–Β–Ϋ―è ―¹―Ä–Β–¥–Ϋ–Η–Ι –¥–Η–Α–Ω–Α–Ζ–Ψ–Ϋ –¥–Μ―è –Ω–Ψ–¥–Ψ–±–Ϋ–Ψ–Ι –Ζ–Α–¥–Α―΅–Η –Ψ–±―΄―΅–Ϋ–Ψ ―¹–Ψ―¹―²–Α–≤–Μ―è–Β―² 0,2-0,45. –ï―¹–Μ–Η –Ψ―¹―²–Α–≤–Η―²―¨ 0,7 ―²–Ψ –Φ–Ψ–Ε–Β―² –Ω–Ψ–Μ―É―΅–Η―²―¨―¹―è ―²–Α–Κ–Ψ–Ι ―Ä–Β–Ζ―É–Μ―¨―²–Α―²:

–ù–Α–Φ –Ε–Β –Ϋ–Β–Ψ–±―Ö–Ψ–¥–Η–Φ–Ψ –Ψ―¹―²–Α―²―¨―¹―è ―΅―É―²―¨ –±–Μ–Η–Ε–Β –Κ –Η―¹―Ö–Ψ–¥–Ϋ–Η–Κ―É, –Ω–Ψ―ç―²–Ψ–Φ―É –≤–Ψ–Ζ―¨–Φ–Β–Φ 0,4.
12. Seed - ―²–Ψ―΅–Κ–Α ―¹―²–Α―Ä―²–Α –≥–Β–Ϋ–Β―Ä–Α―Ü–Η–Η –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è. -1 - –≤―¹–Β–≥–¥–Α ―Ä–Α–Ϋ–¥–Ψ–Φ–Ϋ―΄–Ι ―Ä–Β–Ζ―É–Μ―¨―²–Α―². –ï―¹–Μ–Η –Ω–Ψ–¥―¹―²–Α–≤–Η―²―¨ –Μ―é–±–Ψ–Β –Ω–Ψ–Μ–Ψ–Ε–Η―²–Β–Μ―¨–Ϋ–Ψ–Β ―΅–Η―¹–Μ–Ψ, ―²–Ψ ―Ä–Β–Ζ―É–Μ―¨―²–Α―²―΄ –±―É–¥―É―² –Ω–Ψ―Ö–Ψ–Ε–Η–Φ–Η. –· –Ψ―¹―²–Α–≤–Η–Μ -1 –Η –≥–Β–Ϋ–Β―Ä–Η―Ä–Ψ–≤–Α–Μ –Ω–Ψ–Κ–Α –Ϋ–Β –Ϋ–Α―à―ë–Μ –Ω–Ψ–¥―Ö–Ψ–¥―è―â–Η–Ι.
13. –•–Φ–Β–Φ –Κ–Ϋ–Ψ–Ω–Κ―É Generate.
–Γ–Ψ–±―¹―²–≤–Β–Ϋ–Ϋ–Ψ –≤–Ψ―² –Ω–Α―Ä–Α –Ω–Ψ–Μ―É―΅–Β–Ϋ–Ϋ―΄―Ö –≤–Α―Ä–Η–Α–Ϋ―²–Ψ–≤. –ù–Α –Ψ–¥–Ϋ–Ψ–Φ ―¹–Ψ―Ö―Ä–Α–Ϋ–Η–Μ–Η―¹―¨ ―΅–Β―Ä―²―΄ –Μ–Η―Ü–Α ―¹ –Η―¹―Ö–Ψ–¥–Ϋ–Ψ–≥–Ψ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è, –Ϋ–Α –¥―Ä―É–≥–Ψ–Φ –Ω–Β―Ä―¹–Ψ–Ϋ–Α–Ε ―¹–Φ–Ψ―²―Ä–Η―² –Ω―Ä―è–Φ –≤ –Κ–Α–Φ–Β―Ä―É –Η –≤―΄–≥–Μ―è–¥–Η―² –±―Ä―É―²–Α–Μ―¨–Ϋ–Β–Ι ―΅―²–Ψ –Μ–Η). –ù–Α –Φ–Ψ–Ι –≤–Ζ–≥–Μ―è–¥ ―Ä–Β–Ζ―É–Μ―¨―²–Α―² –Ψ―²–Μ–Η―΅–Ϋ―΄–Ι, –Ω―Ä–Η ―²–Ψ–Φ ―΅―²–Ψ ―è –Ω–Ψ―²―Ä–Α―²–Η–Μ –Ϋ–Α –Ϋ–Β–≥–Ψ –≤―¹–Β–≥–Ψ –Ϋ–Β―¹–Κ–Ψ–Μ―¨–Κ–Ψ –Φ–Η–Ϋ―É―².


–ö―²–Ψ –±―΄ ―΅―²–Ψ –Ϋ–Η –≥–Ψ–≤–Ψ―Ä–Η–Μ, –Ϋ–Ψ –Ϋ–Β–Ι―Ä–Ψ―¹–Β―²–Η ―ç―²–Ψ –±―É–¥―É―â–Β–Β. –‰ –¥–Α, –Φ–Ϋ–Β ―²–Ψ–Ε–Β –Ω–Ψ―Ä–Ψ–Ι ―¹―²―Ä–Α―à–Ϋ–Ψ –Ψ―² ―²–Ψ–≥–Ψ ―¹ –Κ–Α–Κ–Ψ–Ι ―¹–Κ–Ψ―Ä–Ψ―¹―²―¨―é ―Ä–Α–Ζ–≤–Η–≤–Α–Β―²―¹―è ―ç―²–Α ―²–Β―Ö–Ϋ–Ψ–Μ–Ψ–≥–Η―è. –ù–Ψ –Ϋ–Β –Ζ–Α–Φ–Β―΅–Α―²―¨ –Η –Ϋ–Β –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α―²―¨ –Β―ë - –¥–Μ―è –Φ–Β–Ϋ―è ―ç―²–Ψ –Ψ―¹―²–Α―²―¨―¹―è –Ϋ–Α –Ψ–±–Ψ―΅–Η–Ϋ–Β –Η–Ϋ–¥―É―¹―²―Ä–Η–Η. –ù–Α–¥–Β―é―¹―¨ ―¹–Φ–Ψ–≥ –Ψ―²–Κ―Ä―΄―²―¨ –¥–Μ―è –Κ–Ψ–≥–Ψ-―²–Ψ –Ϋ–Ψ–≤―É―é –Ψ–±–Μ–Α―¹―²―¨ –Η –±―΄–Μ–Ψ ―Ö–Ψ―²―¨ –Ϋ–Β–Φ–Ϋ–Ψ–≥–Ψ –Ω–Ψ–Μ–Β–Ζ–Ϋ–Ψ. –£―¹–Β–Φ ―É―¹–Ω–Β―Ö–Ψ–≤ –≤ ―²–≤–Ψ―Ä―΅–Β―¹―²–≤–Β!
–î–Μ―è –Ω―Ä–Η–Φ–Β―Ä–Α –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α–Μ ―Ä–Α–±–Ψ―²―É fox2_87. –Γ–Ω–Α―¹–Η–±–Ψ ―²–Β–±–Β ―΅―²–Ψ ―Ä–Α–Ζ―Ä–Β―à–Η–Μ –≤―¹―²–Α–≤–Η―²―¨ –Β―ë –≤ ―ç―²―É ―¹―²–Α―²―¨―é)