я делал собственные выводы и заключения, не исходя из чьих то, или ваших цитат. )
Не понимаю что сложного проверить это? ссылки ни о чём - цифры и бла бла всё дичь..
Это ведь не сложно сделать тест хотя бы от 16гиг требуемой памяти, чтоб разбить иллюзии (мои или ваши) ? Андрей(Чарли) сделай если не сложно.. это реально будет полезным...
Ибо зайдя на официальный сайт Nvidia - я нигде не вижу таких речей о увеличении памяти 2080ых сериях..
Уверены ли вы, что не путаете увеличение пропускной способности и суммирование видеопамяти ?
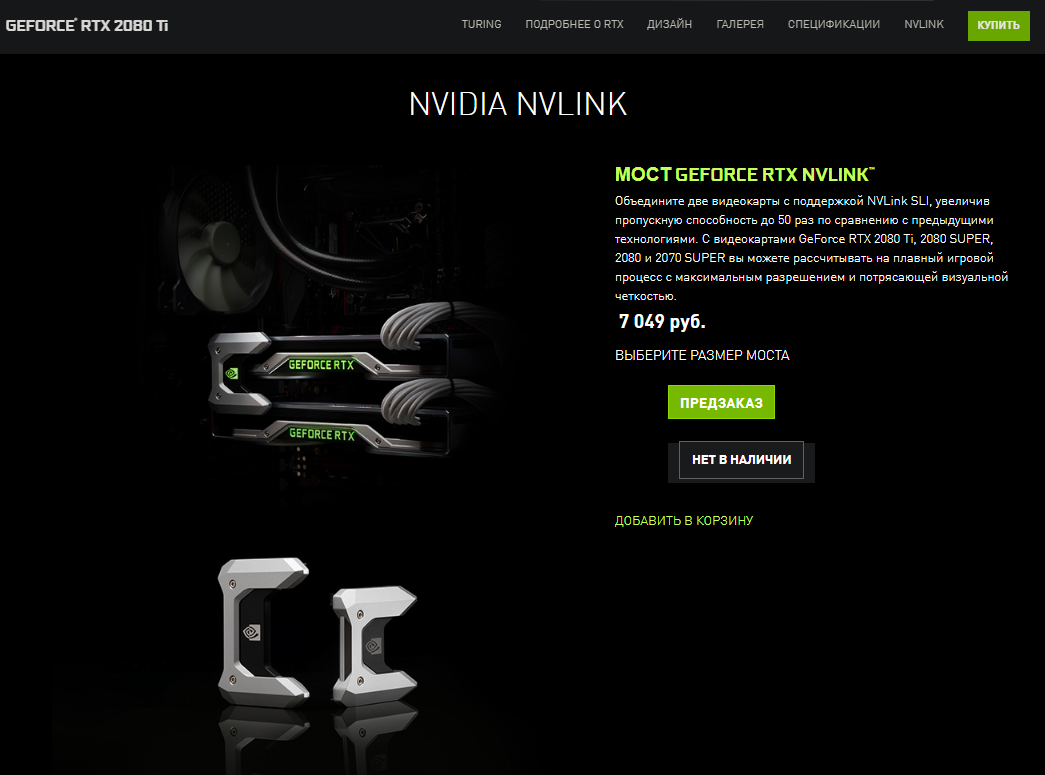
ссылка на офф 2080Ti эти NVLink на этих картах это простой мостик SLI увеличивающий пропускную..
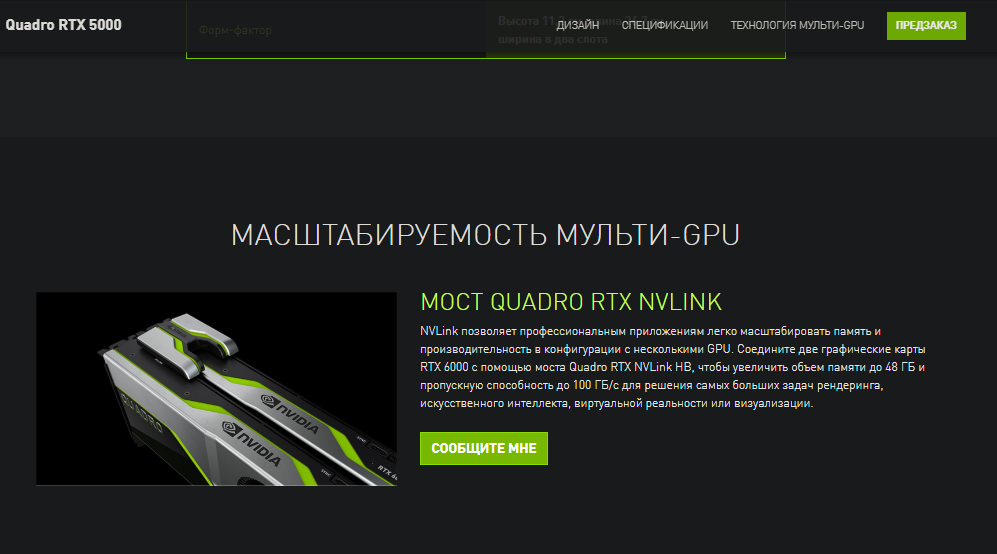
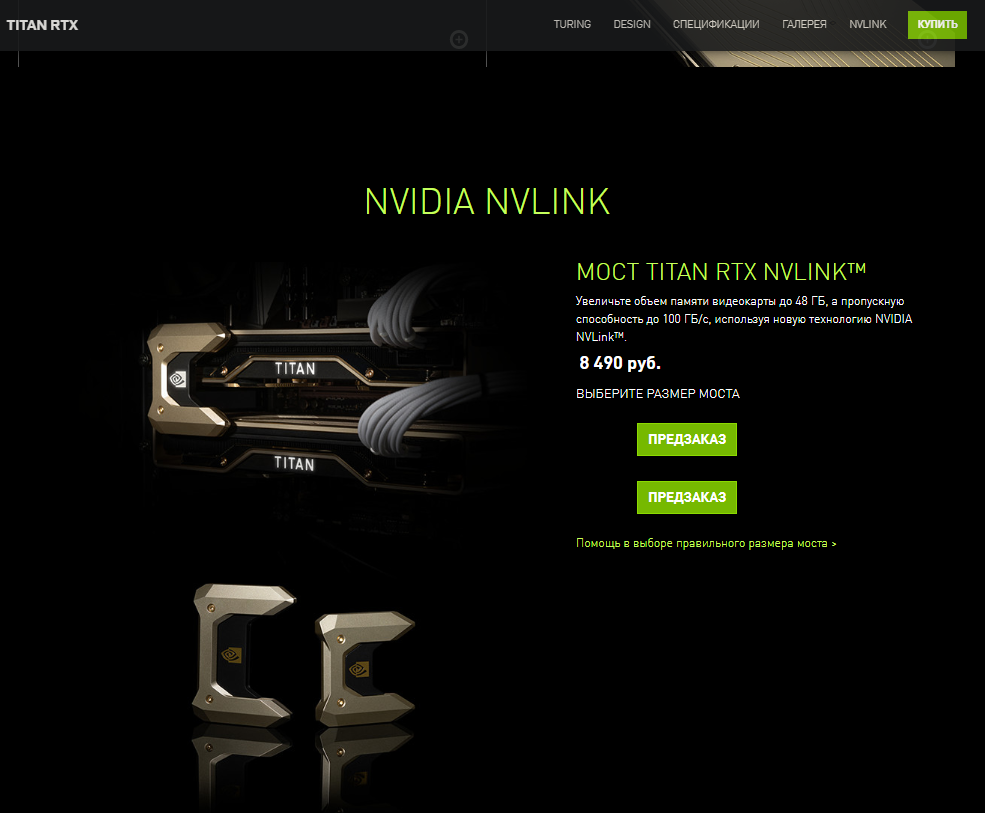
Однако про RTX Quadro и RTX Titan у них как раз таки есть инфа о суммировании памяти.. и мосты эти NVLink уже совсем не те(убогие) как на 2080ках.
с квадрами всё хорошо - лично заявляю без всяких ссылок и другой воды...
Цитата Oleg.budeanu:
Это значит, что 2080 и 2080ti будут работать с NVLink, но только с 2 картами. Хотите 4 - покупайте квадры. Именно это NVidia отключили в последних драйверах.
перейдя по ссылке выше, я вижу последним постом сообщение: которое ведёт на другой ресурс..
Можете прочитать его с самого начала(через транслэйтор) - либо сразу нажмите Ctrl+F и вставьте запрос "GPU rendering and GPU memory".. я лишь процитирую кусок из сказанного там:
"Поэтому, если цена Titan RTX делает вас непростым, одной из альтернатив будет покупка двух карт RTX 2080 Ti. Однако неясно, могут ли графические процессоры GeForce RTX использовать технологию NVLink от Nvidia для объединения памяти графического процессора таким же образом, как карты Titan RTX и Quadro RTX (подробный анализ вы можете найти в этой статье ). В противном случае, даже если некоторые из его 24 ГБ графической памяти используются для работы с дисплеем, один Titan RTX все равно будет более универсальным, чем установка Ti с двумя 2080-ю, в которой на выделенной вычислительной карте будет только 11 ГБ графической памяти. доступно для рендеринга GPU."
Народ, кто попробовал бету, у вас нормально материалы в новой библиотеке отображаются? У меня сами материалы назначаются на объекты, рендер-ок, а вот само превью в прямом смысле - грустное...
тоже самое... :( грустные смайлы на материалах как исправить?
я делал собственные выводы и заключения, не исходя из чьих то, или ваших цитат. )
Не понимаю что сложного проверить это? ссылки ни о чём - цифры и бла бла всё дичь..
Это ведь не сложно сделать тест хотя бы от 16гиг требуемой памяти, чтоб разбить иллюзии (мои или ваши) ? Андрей(Чарли) сделай если не сложно.. это реально будет полезным...
Ибо зайдя на официальный сайт Nvidia - я нигде не вижу таких речей о увеличении памяти 2080ых сериях..
Уверены ли вы, что не путаете увеличение пропускной способности и суммирование видеопамяти ?
ссылка на офф 2080Ti эти NVLink на этих картах это простой мостик SLI увеличивающий пропускную..
Однако про RTX Quadro и RTX Titan у них как раз таки есть инфа о суммировании памяти.. и мосты эти NVLink уже совсем не те(убогие) как на 2080ках.
с квадрами всё хорошо - лично заявляю без всяких ссылок и другой воды...
Цитата Oleg.budeanu:
Это значит, что 2080 и 2080ti будут работать с NVLink, но только с 2 картами. Хотите 4 - покупайте квадры. Именно это NVidia отключили в последних драйверах.
перейдя по ссылке выше, я вижу последним постом сообщение: которое ведёт на другой ресурс..
Можете прочитать его с самого начала(через транслэйтор) - либо сразу нажмите Ctrl+F и вставьте запрос "GPU rendering and GPU memory".. я лишь процитирую кусок из сказанного там:
"Поэтому, если цена Titan RTX делает вас непростым, одной из альтернатив будет покупка двух карт RTX 2080 Ti. Однако неясно, могут ли графические процессоры GeForce RTX использовать технологию NVLink от Nvidia для объединения памяти графического процессора таким же образом, как карты Titan RTX и Quadro RTX (подробный анализ вы можете найти в этой статье ). В противном случае, даже если некоторые из его 24 ГБ графической памяти используются для работы с дисплеем, один Titan RTX все равно будет более универсальным, чем установка Ti с двумя 2080-ю, в которой на выделенной вычислительной карте будет только 11 ГБ графической памяти. доступно для рендеринга GPU."
Чтобы вы много не переводили, ответ прост : во вьюпорте октана показывается 11 GB памяти, потому что Октан так сделан, что он сначала использует память одной видеокарты, потом начинает использовать NVLink и память со второй. Это потому, что прямой доступ к памяти видеокарты, на которой начинаются вычисления намного быстрее, чем с NVLink к памяти второй. Нужно понимать, что NVLink не объединяет чудесным образом память. Он позволяет использовать память второй видеокарты как дополнительный буффер, при переполнении первого. Имплементация этого - полностью зависит от софта.
Вы столько пишете, что де ссылки и вода и т.д. Но в них-то вся и суть, просто внимательней читайте и ищите.
Чтобы вы много не переводили, ответ прост : во вьюпорте октана показывается 11 GB памяти
у меня встроенный переводчик в Chrome ))
В общем по факту своими словами - это тот же OutOfCore только из памяти другой видеокарты.. (нужно сначала исчерпать память одной видюхи) и они так же утверждают , что и скорость падает.. осталось только выяснить на сколько именно падает скорость.. что там так же по PCI-Lines происходит при загрузке текстур в память.. интересно.. тэсты чайников уникальных копий - всё хрень.. тесты нужны в том числе в виде текстур от 4к и выше.
Поэтому я и не хотел тупо смотреть на цифры, лучше один раз увидеть(в виде примера на рендере) чем 100 постов посмотреть..
Теперь поправьте меня - верно ли, что они выпустили этот мост только на две видео карты? тройник слепить уже нельзя?
Сравнить их (2x2080Ti vs RTX Titan).. на примере скорости рендера - но конечно нужно выйти за предел памяти гиг на 16 (на Rtx 2080Ti).. если они всё же покажут лучшее время рендера, чем Titan - то всё это имеет большой смысл.
Цитата Oleg.budeanu:
Нужно понимать, что NVLink не объединяет чудесным образом память
я вам это и пытался объяснить с историей про 2080Ti ))
А во чудесным образом он объединяет видеопамять на сериях Titan RTX, и RTX Quadro....
Чтобы вы много не переводили, ответ прост : во вьюпорте октана показывается 11 GB памяти
у меня встроенный переводчик в Chrome ))
В общем по факту своими словами - это тот же OutOfCore только из памяти другой видеокарты.. (нужно сначала исчерпать память одной видюхи) и они так же утверждают , что и скорость падает.. осталось только выяснить на сколько именно падает скорость.. что там так же по PCI-Lines происходит при загрузке текстур в память.. интересно.. тэсты чайников уникальных копий - всё хрень.. тесты нужны в том числе в виде текстур от 4к и выше.
Поэтому я и не хотел тупо смотреть на цифры, лучше один раз увидеть(в виде примера на рендере) чем 100 постов посмотреть..
Теперь поправьте меня - верно ли, что они выпустили этот мост только на две видео карты? тройник слепить уже нельзя?
Сравнить их (2x2080Ti vs RTX Titan).. на примере скорости рендера - но конечно нужно выйти за предел памяти гиг на 16 (на Rtx 2080Ti).. если они всё же покажут лучшее время рендера, чем Titan - то всё это имеет большой смысл.
Цитата Oleg.budeanu:
Нужно понимать, что NVLink не объединяет чудесным образом память
я вам это и пытался объяснить с историей про 2080Ti ))
А во чудесным образом он объединяет видеопамять на сериях Titan RTX, и RTX Quadro....
Другими словами не нужно говорить, это две разные вещи.
Out Of Core работает с памятью RAM.
NVLink - с памятью видеокарты и пропускная способность там выше в разы.
И на Titan и Quadro он чудесным образом не объединяет. Я имею ввиду, что в перую очередь тут вопрос про имплементацию. Понимаете, это мост. Чем чаще данные бегают по этому мосту - тем медленнее процесс. Так вот, все стараются сделать так, чтобы "бегать" нужно было как можно реже. Поэтому заполняют буфер "родной", а потом "соседний".
Иначе, беготня туда сюда с одновременным заполнением будет медленнее.Quadro и прочие работают немного по другому, честно не знаю как именно, но думаю там какие-то дополнительные фишки для работы с множеством карточек.
Чудесное "объединение" будет только если производители мат. плат прийдут на помощь и внедрят это как стандарт. Мне кажется, в будущем это неизбежно, просто потому что всё переходит на GPU. Но для стандарта NVidia нужно скинуть с постамента монополиста. Так что надо поддерживать AMD :)
Цитата grdesigner:
Тут еще такая тема подъехала вчера. Пока ничего непонятно, но очень интересно.
Да, я первую бету смотрел. Крутая штука для презентаций.
Oleg.budeanu, я только по роликам смотрел. В новостях на рендере пару месяцев назад пробегала, но то была версия 0.х какая-то там. Особо значения не придал. А здесь уже 2.3. Быстро развивается.
Пока еще не совсем ясно, как это все в рабочий процесс втыкать и какие возможности, но выглядит интересно.
Другими словами не нужно говорить, это две разные вещи. Out Of Core работает с памятью RAM. NVLink - с памятью видеокарты и пропускная способность там выше в разы.
Да вы вообще далеки видимо от понимания этих вещей.. физически с этим мостом у вас по факту также две карты, память второй карты юзают для обмена данных, когда памяти первой не хватает для рендера.
OutOfCore это выход за пределы памяти, он не подразумевает в себе понятие, куда именно выходить в RAM или в СВОП с винта или в память другой видеокарты, как в этом случае..
Скорость падает это факт, остаётся только понять на сколько именно.. Вы аналогично выходите за пределы памяти (RAM) в Corona Render - уходя в своп с жёсткого диска, скорость падает в ЩИ.. также и это тоже можно отнести к понятию OutOfCore.
Цитата Oleg.budeanu:
И на Titan и Quadro он чудесным образом не объединяет. Я имею ввиду, что в перую очередь тут вопрос про имплементацию. Понимаете, это мост. Чем чаще данные бегают по этому мосту - тем медленнее процесс. Так вот, все стараются сделать так, чтобы "бегать" нужно было как можно реже. Поэтому заполняют буфер "родной", а потом "соседний".
Цитата Oleg.budeanu:
Иначе, беготня туда сюда с одновременным заполнением будет медленнее.Quadro и прочие работают немного по другому, честно не знаю как именно, но думаю там какие-то дополнительные фишки для работы с множеством карточек.
Дак вы знаете или не знаете? )) вы запутались определённо в мостах, терминах и постах..
У вас есть RTX QUADR'ы? )) У нас то они есть.. почему вы мне тогда рассказываете, как складывается в ней память? ))
Для вас же Nvlink это просто слово ) вы даже не понимаете, что эти мосты делятся на классы.. и тот NVLink для 2080ti это не полноценный NVLink (это простой SLI на новом интерфейсе под NVLink соединение).. Иными словами чтоб вы переплачивали за них! В итоге имея старый SLI в новой обвёртке.. маркетинг.
Oleg.budeanu, я только по роликам смотрел. В новостях на рендере пару месяцев назад пробегала, но то была версия 0.х какая-то там. Особо значения не придал. А здесь уже 2.3. Быстро развивается.
Пока еще не совсем ясно, как это все в рабочий процесс втыкать и какие возможности, но выглядит интересно.
Экспорт в vrscene, со всеми вытекающими. А там уже рендер на карточке RTX. Я не то, чтобы много пробовал, но пока это мне не совсем интересно. Хоть выглядит круто. Как я и говорю - для презентаций самое оно, выбрать с клиентом камеру, показать несколько вариантов в лайве. Этакий интерактив.
Вообще мне кажется ChaosGroup заинтересовал путь Maxwell Render , где они сделали свой Maxwell Studio. Мне кажется это что-то близкое к этому. Возможно им надоели капризы автодеска. Своя студия решит проблему рендера для Blender и других пакетов.
Возможности довольно обширные и интересные, на самом деле.
Да вы вообще далеки видимо от понимания этих вещей.. физически с этим мостом у вас по факту также две карты, память второй карты юзают для обмена данных, когда памяти первой не хватает для рендера.
А я что сказал? Именно это и сказал.
Цитата StunBreaker:
OutOfCore это выход за пределы памяти, он не подразумевает в себе понятие, куда именно выходить в RAM или в СВОП с винта или в память другой видеокарты, как в этом случае..
"Out-of-core textures allow users to use more textures than would fit in the graphic memory (VRAM), by keeping them in the host memory (RAM). The data for rendering the scene needs to be sent to the GPU while rendering so some tradeoff in the rendering speed is expected. This also means that as the CPU accommodates requests to access the host memory, CPU usage will increase and any RAM occupied with out-of-core textures will not be available to other applications."
Цитата StunBreaker:
Скорость падает это факт, остаётся только понять на сколько именно.. Вы аналогично выходите за пределы памяти (RAM) в Corona Render - уходя в своп с жёсткого диска, скорость падает в ЩИ.. также и это тоже можно отнести к понятию OutOfCore.
Бульдоги с носорогами.... не зря есть определённые понятия для каждой процедуры. Out of core это Out of core, а SWAP и Virtual Memory это другое, хватит мешать всё вместе! Найдите документацию и прочитайте внимательно.
Ладно, вы явно не хотите смотреть ссылки, которые я даю, я не понимаю, зачем я это делаю тогда.
Я вам уже и как ребёнку объяснил, как работает NVLink. Конечно, есть разные коннекторы, с разной пропускной способностью, но всё зависит от ИМПЛЕМЕНТАЦИИ КОДА. Понимаете? Если вы сделает, что софт НЕ БУДЕТ ВИДЕТЬ МОСТ 2 ВИДЕОКАРТ КАК ОДНО ЦЕЛОЕ , то он так и будет работать! В Octane именно так и сделано! При переполнении буфера - снижается скорость, задействуется NVLink и грузится память второй видеокарты.
Если у вас RTX карты, то какого вы морочите голову ??? Запустите тяжелую сцену и покажите тесты.
Экспорт в vrscene, со всеми вытекающими. А там уже рендер на карточке RTX. Я не то, чтобы много пробовал, но пока это мне не совсем интересно. Хоть выглядит круто. Как я и говорю - для презентаций самое оно, выбрать с клиентом камеру, показать несколько вариантов в лайве. Этакий интерактив. Вообще мне кажется ChaosGroup заинтересовал путь Maxwell Render , где они сделали свой Maxwell Studio. Мне кажется это что-то близкое к этому. Возможно им надоели капризы автодеска. Своя студия решит проблему рендера для Blender и других пакетов. Возможности довольно обширные и интересные, на самом деле.
Я правильно понимаю, что это Standalone VRay? По типу кейшота, мармосета?
Я вам уже и как ребёнку объяснил, как работает NVLink
дак это вы мне объясняли всё это время? )))
Цитата Oleg.budeanu:
Конечно, есть разные коннекторы, с разной пропускной способностью, но всё зависит от ИМПЛЕМЕНТАЦИИ КОДА. Понимаете?
да они на уровне железа не могут этого делать
Я про пропускную и ничего не писал, на QUADRO она зашкаливает..
Цитата Oleg.budeanu:
Если у вас RTX карты, то какого вы морочите голову ??? Запустите тяжелую сцену и покажите тесты
Почему я морочу вам голову, если вы просто не внимательны? ))
Я же фото скидывал с ними со своего рабочего стола ещё несколько страниц назад. вы где были? именно их полноценное соединение NVLink я и брал в пример для сравнения.
И с первого сообщения объяснял, что это не суммирование видео памяти (в вашем случае) а заимствование памяти второй видеокарты для обмена данных во время рендера.
В каком виде оно на Octane опять же не понятно, на сколько падает скорость?? а если в 2 раза?? я не видел там видео тестов в виде рендеров, или я что-то пропустил?
Зачем мне запускать сцену, чтоб убедиться в чём? ) я их через день запускаю на разных машинах )) полная физическая доступная видеопамять 32гига.
p.s. прочитайте просто мой первый пост ещё раз на этой странице.. я не понимаю - что я вам всё ещё доказываю? на этом предлагаю закончить этот видимо уже спор )) даже если вы всё ещё так же не согласны..
3. "Однако неясно, могут ли графические процессоры GeForce RTX" - на этот вопрос вам ответили - 2080 могут, по такому же методу, разница только в пропускной способности, НО не больше 2 видеокарт.
4. "Titan RTX все равно будет более универсальным, чем установка Ti с двумя 2080-ю, в которой на выделенной вычислительной карте будет только 11 ГБ графической памяти. доступно для рендеринга GPU." - это я вам тоже объяснил на примере имплементации Octane.
5. Out of Core - вы заблудились в понятиях, я вам объяснил в чем разница Out Of Core, VRam, SWAP и т.д.
6. Вы постоянно гадаете "осталось только выяснить на сколько именно падает скорость", "тесты нужны в том числе в виде текстур от 4к и выше.", "Поэтому я и не хотел тупо смотреть на цифры, лучше один раз увидеть(в виде примера на рендере) чем 100 постов посмотреть.. "Но при этом "Зачем мне запускать сцену, чтоб убедиться в чём? ) я их через день запускаю на разных машинах )) полная физическая доступная видеопамять 32гига. ".
Так что вы пудрите мозги-то ? Вы получили ответы на все вопросы, я развеял ваши сомнения, указал что означают определения. У вас есть карточки и вы на них работаете каждый день, рендерите там на разных машинах и прочее. Так купите NVLink (если у вас его нет), установите демо Octane, сделайте форестом сцену на сотню миллионов полигонов и отрендерите. Хотите сравнить 2х2080Ti NVLink с Titan RTX NVLink? Ну тогда спросите у людей у кого есть в GPU форуме того же ChaosGroup или Octane и сравните, а нам расскажете.
Хоспаде. Всё, это мой последний пост на эту тему, дальше уже некуда.
А по теме
Баг с VRayLightMTL в мультимате не пофиксили.
Надеюсь к релизу VRay 5 пофиксят.
Если у вас появляются пятна в превью материалов - это в разработке, там используются низкие настройи ирмапы, и, в частности, с VrayLightMTL - могут быть пятна.
NVIDIA® NVLink™ is the world's first high-speed GPU interconnect offering a significantly faster alternative for multi-GPU systems than traditional PCIe-based solutions. Connecting two NVIDIA® Quadro® graphics cards with NVLink enables scaling of memory and performance1 to meet the demands of your largest visual computing workloads.
Там же таблица по QUADRO только ! да в таблице указана разница пропускных способностей по ним, а какая связь между 2080, чтоб приводить в сравнение эту ссылку и уж тем более связь между суммированием памяти ???? Опять не догоняете сути своих же ссылок.
Найдите официальную инфу от NVIDIA - чтоб они заявили там о суммировании видеопамяти на 2080ках..
А пока вы это всё перевариваете ещё раз обращаю ваше внимание на разницу ))
Этот мост NVLink SLI (на 2080ках) только пропускную способность увеличивает.. как в принципе и было на первых мостах SLI.. пропускная способность так же зависит от скорости PCI Lanes.. Боюсь вы ещё больше запутаетесь в этом... )
не надо путать заслуги отоя, что они там что-то намудрили для того, чтоб как то перегонять данные в память другой видеокарты с потерей скорости(из за этих перегонок) и то только КОГДА ОНИ УПЁРЛИСЬ В ЛИМИТ ВИДЕОПАМЯТИ на первой карте !!! Да это же КОСТЫЛЬ - неужели вы этого не понимаеете??
В то время как по RTX QUADRO, и RTX TITAN имеете не только увеличение пропускной способности, но и физически доступную видеопамять от двух видеокарт.. я ребёнку своему так не объясняю как вам ))
Ещё раз настоятельно предлагаю уже закрыть этот спор.. пусть тогда каждый остаётся при своём мнение.